はじめに
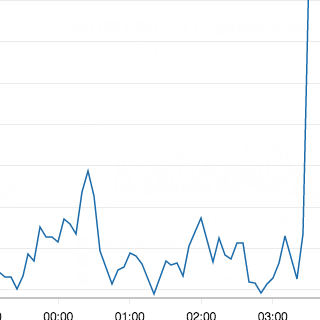
AWSで稼働しているAmazonLinuxのdiskサイズが枯渇した
原因
何かが肥大化しているのが通例なので、duコマンドで調べていったら
/var/log/awslogs.log
が数ギガ使っていたということにたどり着いた
もちろんログローテートはしているが、数ギガ使っているというのは明らかに異常
何がawslogs.logに書き込んでいるか。
Linuxにある各種ログファイルを
CloudWatchMonitoringScripts
http://aws-cloudwatch.s3.amazonaws.com/downloads/CloudWatchMonitoringScripts-1.2.1.zip
を用いてCloudWatchに送っているが、このスクリプトが送信した情報は
/var/log/awslogs.log
に書かれる。これが肥大化していた
どのようなエラー内容か
/var/log/awslogs.log
をtailで見ると、以下のようなログが出力されていた。
ClientError: An error occurred (AccessDeniedException) when calling the PutLogEvents operation: User: arn:aws:iam::****:user/**** is not authorized to perform: logs:PutLogEvents on resource: arn:aws:logs:ap-northeast-1:****:log-group:/var/log/cron/cron:log-stream:ALL
AccessDeniedException
をみて、awsコマンドの設定周りが怪しいとあたりがついた
awsのconfigについて
前途した通り、LinuxサーバはCloudWatchMonitoringScriptsを用いてログを送付しているが、
設定ファイルは/etc/配下に格納している。
それぞれ、awsコマンドを使う上での環境設定ファイルと、監視対象のログを記載したファイル
[plugins]
cwlogs = cwlogs
[default]
region = ap-northeast-1
aws_access_key_id=***
aws_secret_access_key=***
[general]
state_file = value
logging_config_file = value
use_gzip_http_content_encoding = false
[/var/log/maillog/maillog]
datetime_format = %b %d %H:%M:%S
file = /var/log/maillog/maillog
buffer_duration = 5000
log_stream_name = ALL
initial_position = start_of_file
log_group_name = /var/log/maillog/maillog
設定自体は問題なさそう。
原因
/etc/awslogsが最初に呼ばれるわけではない。
起動ユーザーの.awsディレクトリ配下が先に呼ばれる。
そのため、.awsディレクトリが存在していると、
ログが送れないなどの事象が発生する。
[default]
中身は[default]しか書かれていなかったが、設定ファイルが存在していた。
これが存在していたことにより、/etc/awslogsディレクトリが読み込まれず、Cloudwatchに送付できていなかったようだ。
対処
空の.awsディレクトリを削除し、awslogsを再起動
正常にcloudWatchにログが送付され、DISKの肥大化も解消した
参考情報
本記事のみならず、AWSについて体系的に学ぶことができるのでおすすめ。