
CloudWatch Logsエージェントがデフォルトでデータを送信する頻度
5秒ごと
CloudWatchの無料枠で受け取る事ができるメトリックアップデートの頻度
5分
受信および集計するデータの最小時間間隔
1分
AWSの情報をまとめる

5秒ごと
5分
1分
単一のVPCにパブリックサブネットが1つデフォルトで設定される
VPCを設置しないでEC2インスタンスを立ち上げる場合、サブネットの設定が必須になる
グローバルIPを持つAWSサービスに対して、VPCの内部から直接接続するための出口。
Gateway型はサブネットに特殊なルーティングを設定し、VPC内部から直接外のサービスと通信する
VPC peeringは一部のリージョン間に限られている。
サブネットにエンドポイント用のプライベートIPを設定して使用する
エンドポイントポリシーによりアクセス制御を実施
accepted/rejectedされたトラフィックを保持する
10分間で収集・プロセッシング・保存する
VPC内の全てのIPアドレスを利用している場合は、VPCのCIDRブロックを変更して、新しいサブネットに十分な空きスペースを作成する事で枯渇時対処することも可能。
セキュリティを高める際に利用する
具体的には、アプリケーションが動いているインスタンスは他のAWS顧客とハードウェアを共有してはいけない場合、以下の構成を検討する事ができる
Amazon RDS MySQL DBインスタンスで現在、利用可能な最大のインスタンスタイプで実行されているとする。
DBインスタンスはCPUおよびネットワーク帯域幅に近いキャパシティで動作。
今後、トラフィックが増加することを予想される。より多くのトラフィックを捌くアプローチ
プライマリDBインスタンスに障害が発生した場合、RDSマルチアベイラビリティゾーンのデプロイは、
標準名レコード(CNAME)がプライマリからスタンバイに変更される。
セッション情報をRDSではなく、ElasticCacheを利用する際の挙動
追加ストレージを割り当てる事が可能。割り当て中にパフォーマンスが低下する期間を計画する。

dynamodbへまとめてデータを入れたい時がある。バルクインポートの手順を紹介
{
"tsukada-tw": [
{
"PutRequest": {
"Item": {
"ID": {"N":"1"},
"Tip": {"S":"【保存版】プレゼンで使えるグラフや図を表現する英語フレーズ集 https://www.rarejob.com/englishlab/column/20190426/"
}
}
}
},
{
"PutRequest": {
"Item": {
"ID": {"N":"2"},
"Tip": {"S":"海外でも母の日は祝うもの? Mother’s Dayの時期や英語のお祝いメッセージを紹介! https://www.rarejob.com/englishlab/column/20190425/"
}
}
}
},
{
"PutRequest": {
"Item": {
"ID": {"N":"3"},
"Tip": {"S":"英文メールの結びにはなんて書けばいい?ビジネスからカジュアルまで「よろしく」や「敬具」に代わる結びの英語表現まとめ https://www.rarejob.com/englishlab/column/20190424/"
}
}
}
}
]
}
aws dynamodb batch-write-item --request-items file://bulk.json


資格こそ取っていないが、AWSは常に触っている。試験を受ける受けないは別にして、知識をあるレベルまで引き上げる上で、試験用の本から多くのことを学ぶことができる。
今回は「徹底攻略AWS認定ソリューションアーキテクトアソシエイト教科書」を通じて得られた知識についてまとめた。
| mode | 解説 |
|---|---|
| 迅速 | オンデマンドと呼ばれる。 成功する保証がない |
| 標準 | 3~5時間でアーカイブから取り出しが可能 |
共有ストレージ。ユーザー側でスナップショット取得不可
エフェメラルディスクとも呼ばれる。EC2停止時にはデータは消失。再起動では消失しない
データは3箇所のAZに格納される
1つのAZにつき2箇所のディスクに書き込まれる => 合計6箇所に保存される
結果整合性モデルが一部採用されている
| メソッド | 種別 | 特徴 |
|---|---|---|
| PUT | 新規追加 | 書き込み後の、読み込み整合性 |
| PUT | 更新 | 結果整合性 |
| DELETE | 削除 | 結果整合性 |
メッセージの送信、受信のアクセスポイント
TOPICを作成し、購読者が購読することで通知の送受信が可能になる
TOPICから発信されるメッセージの購読者を設定
の利用が可能
作成したTOPICに対してアプリケーションからメッセージを送信。
送信されたメッセージはSQSから購読者(サブスクライバ)へ配信される
定義ファイルをテンプレートと呼ぶ
テンプレートから呼び出されるサービスの集合を、スタックと呼ばれる
システムが正常に継続して動作し続ける能力
指標はパーセンテージ。一般的に稼働率と呼ばれる。
スケーリングプラン設定値が閾値超え
↓
EC2インスタンスを増加(Auto Scalingグループの設定値に従う)
EC2インスタンス数が最も多いAZからランダムに選ばれる
もしインスタンス数が同じ場合は、最も古いEC2インスタンスがあるAZが選ばれる
それも同じ場合は、次に課金が発生する時間が最も短いEC2インスタンスが選ばれる
それも同じ場合は、この中からランダムに選ばれる
Auto Scalingが連続で実施されないようにする待ち時間
アプリケーションのバグや、オペレーションミスの場合、RDSの自動再起動を行う。
フェールオーバでの復旧が不可能な場合、バックアップからのリストアをする必要がある。
標準のスナップショット機能を用いる
EBS もしくは AMIで取得したバックアップを用いて、リストアを行う
単一のAZ内のEC2インスタンスを論理的にグルーピング
複数のコンピューティングリソースを1つとして機能させる。
クラスターコンピューティングに最適
EC2 ⇔ EBS間
EC2 ⇔ その他が同一のネットワークになる
EC2 ⇔ EBS間が専用のネットワークになる
DynamoDBのインメモリキャッシュ。
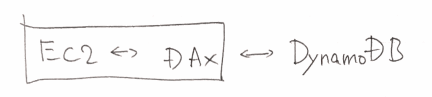
のように使う
Google/FacebookなどのOpenID Connectをサポート
どちらもユーザがAWSで鍵を管理・保管するサービス
クライアントサイド(CSE)
サーバサイド暗号化(SSE)
AWSのサービスでは、Deployができるサービス、Provisioningができるサービス、その両方が可能なサービスが存在する。まとめると以下の通り。
| Service | Deploy | Provisioning |
|---|---|---|
| OpsWork | ○ | ○ |
| Elastic Beanstalk | ○ | ○ |
| Code Deploy | ○ | × |
| Cloud Formation | × | ○ |
Consolidated Billing(一括請求)で統合可能
メンバーのアカウント(Linked Account)の請求を、
マスターのアカウント(Payer Account)に統合できる

fargateでタスクを登録し、起動させた時エラーが発生。原因と対処をまとめる
An error occurs when a task is registered and started with fargate. Summarize causes and actions
CannotStartContainerError: API error (500): failed to initialize logging driver: failed to create Cloudwatch log stream: ResourceNotFoundException: The specified log group does not exist. status code: 400,
CloudWatch のロググループが存在しない
CloudWatch log group does not exist
CloudWatchにロググループを作成する
Create a log group in CloudWatch
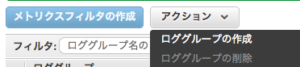
その後、再度タスクを実行すれば問題は解消できる。
After that, the problem can be solved by executing the task again.
ディスクサイズを確認する
$ df -h Filesystem Size Used Avail Use% Mounted on /dev/xvda1 20G 20G 291M 99% /
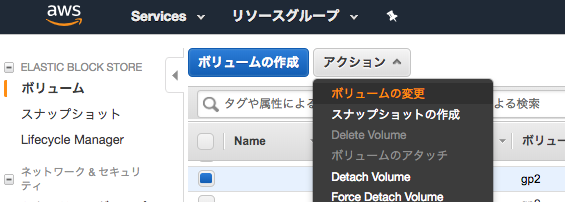
何ギガに増やしたいのかサイズを指定する
(増やす容量ではなく、現在のDISKと併せてトータルの容量にする)
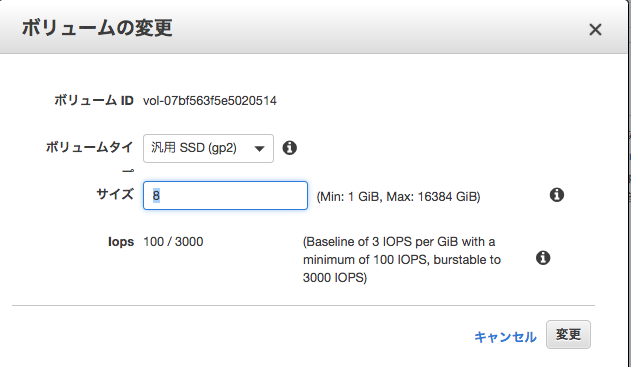
ブロックデバイスの一覧を表示する
$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 40G 0 disk └─xvda1 202:1 0 20G 0 part /
ブロックデバイスを拡張する
(ここの手順がAmazon Linux1と2で異なる)
以下の手順はAmazon Linux2。
$ sudo growpart /dev/xvda 1 CHANGED: disk=/dev/xvda partition=1: start=4096 old: size=41938910,end=41943006 new: size=83881950,end=83886046
ブロックデバイス一覧を表示する。
変更された事を確認する。
$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 40G 0 disk └─xvda1 202:1 0 40G 0 part /
パーティションを拡張する
$ sudo xfs_growfs /dev/xvda1
meta-data=/dev/xvda1 isize=512 agcount=11, agsize=524159 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=5242363, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 5242363 to 10485243
パーティションが拡張された事を確認する
$ df -h Filesystem Size Used Avail Use% Mounted on /dev/xvda1 40G 20G 21G 50% /
https://dev.classmethod.jp/cloud/aws/expand-ebs-in-online/

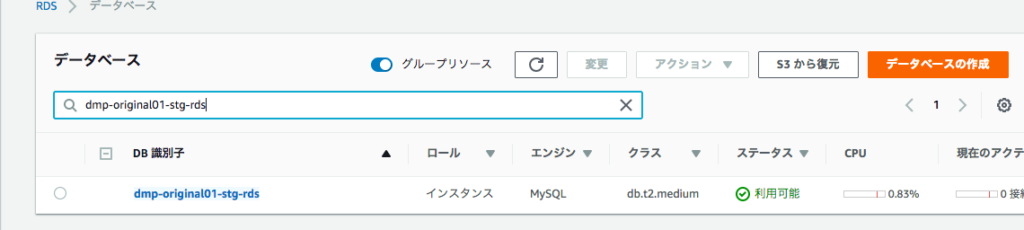
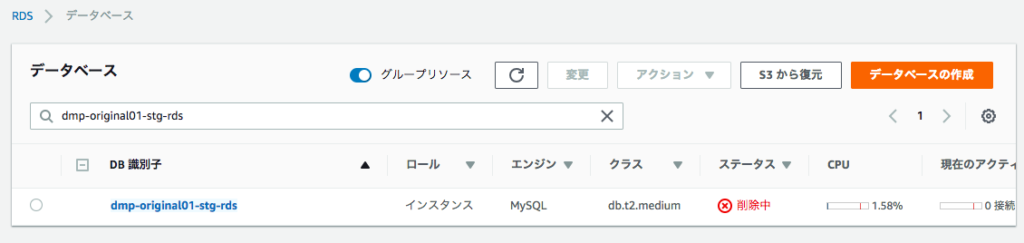
RDSをaws cliで削除したいことがある。認証さえ登録されていれば1行でできる。
普通にdatabaseが消えるので要注意。
aws rds delete-db-instance --db-instance-identifier [インスタンス名] --skip-final-snapshot
route 53の登録をコマンドで実行したい時がある。
コマンドをまとめる。
jsonファイルを作成
{
"Changes": [
{
"Action": "UPSERT",
"ResourceRecordSet": {
"Name": "server-original.stg.rds.sumito.jp",
"TTL": 300,
"Type": "CNAME",
"ResourceRecords": [
{
"Value": "server-original-stg-rds.aaaddcda.ap-northeast-1.rds.amazonaws.com"
}
]
}
}
]
}
#変数登録
DB_JSON=create_db.json
HOST_ZONE_ID=`aws --profile staging route53 list-hosted-zones | jq -r '.[][] | select (.Name == "stg.rds.sumito.jp.") | .Id'`
SDBM_ID=`aws --profile staging route53 change-resource-record-sets --hosted-zone-id ${HOST_ZONE_ID} --change-batch file://${DB_JSON} `
echo $SDBM_ID | jq -r '.ChangeInfo.Status' PENDING
定期的にコンテナを立ち上げて処理を流したい。
AWS batch + ECRというアプローチもあれば、fargate (EC2)でタスクスケジュールというアプローチもあります。
それぞれメリットデメリットをまとめました。
aws batch 実態はEC2であります。
CloudWatch Eventにより発火させることがユースケースとしては多いようです。
AWS batchがEC2を起動して、コンテナをとってきて、、、という作業になるため、
10分ほどかかる可能性があります。
EC2のスポットインスタンスを利用することもできます。
当然スポットインスタンスなので、突然処理が止まってしまう事もありますが、
AWS batchには最大5回のリトライ設定も可能。
jobのキューイング機能もあります。
diskが難しくなったらEBSを増やせばよいというのも強みの一つです。
ただし現状、EFSとかをattachできません。
retry処理はありません。
AWS Step Functionsと組み合わせることができ、そちらでリロードすることは可能です。
LambdaとLambdaを繋げるのに使われることが多いですが
step functions にfargateを使うことで、ジョブをコントロールすることが可能です。
fargateのdiskは10G それ以上増やすことは現状できません。
fargate/EC2 ログは標準出力になります。
AWS batchでもfargateでもdocker imageを作る必要があります。
その作成のベストプラクティスについて
CodePilpelineを使い以下のフローの中でコンテナのpushまで入れます。
* source code
* ビルド
* デプロイ
を一貫して行うことができます。
コンテナ作れる人に適切にroleを設定します
コンテナを作る環境を作り、そこでroleを付与します。
タスクのところで環境変数で持てるので、
そこで適当な文字を入れます(仮にAAAAA)。
Secret manager に適当な文字(仮にAAAAA)と、実際のパスワードを記載することでcredential の管理が可能です。![]()
AWSについて体系的に学ぶことができるのでおすすめ。