

はじめに
Firebase AuthenticationにFacebook Accountでログインを有効にさせる方法をまとめます。
設定
Facebook for Developers(以下Facebook)にログインして、アカウントのセットアップをします
https://developers.facebook.com/?locale=ja_JP
Firebaseのログインプロバイダの画面で「Facebookログイン」を有効にします。
Facebook側のページに戻り、左側の設定のからベーシックを押し、アプリID/app secretを確認します。
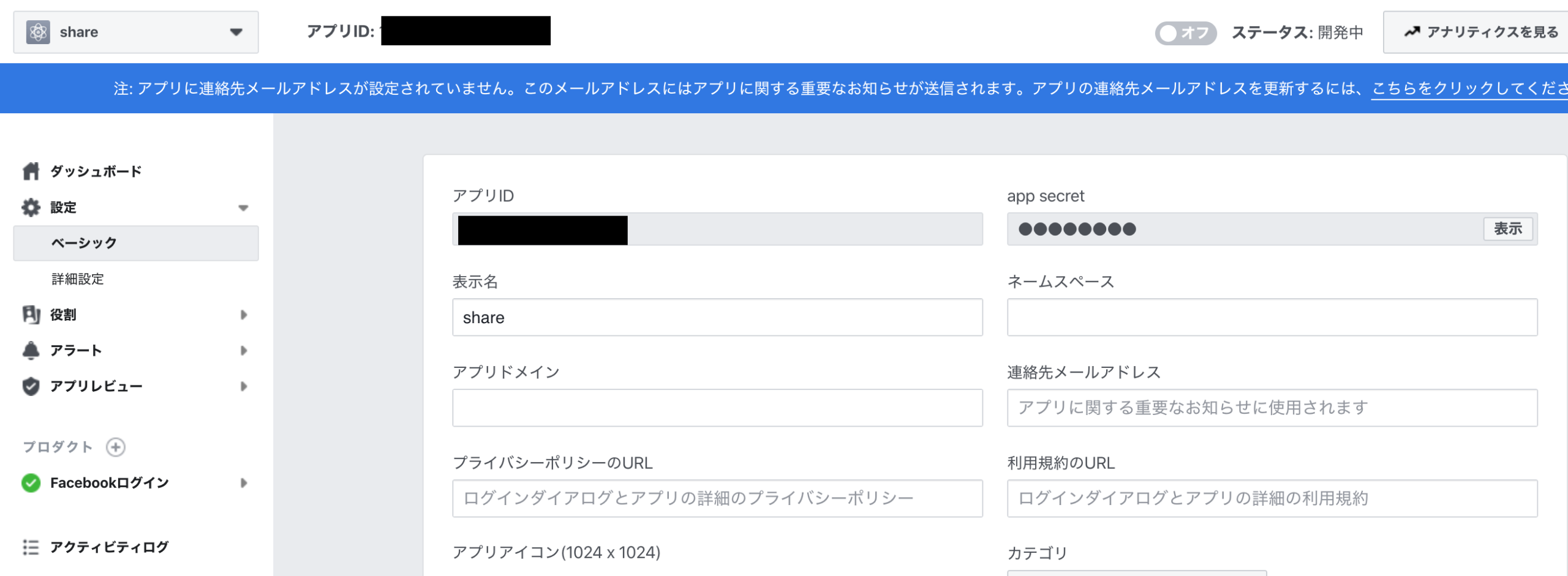
Firebase側に戻り、それぞれ埋めます。

Facebookでクイックスタートからウェブを選択します。
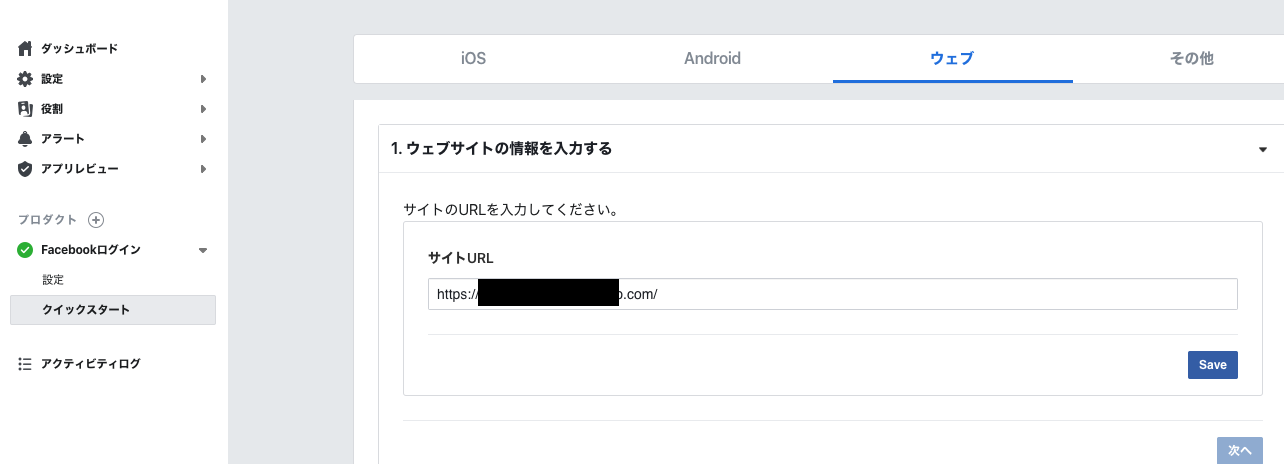
WebアプリケーションのURLを入力。
Firebaseの画面に表示されているOAuth リダイレクト URI を Facebook アプリの設定に追加します。
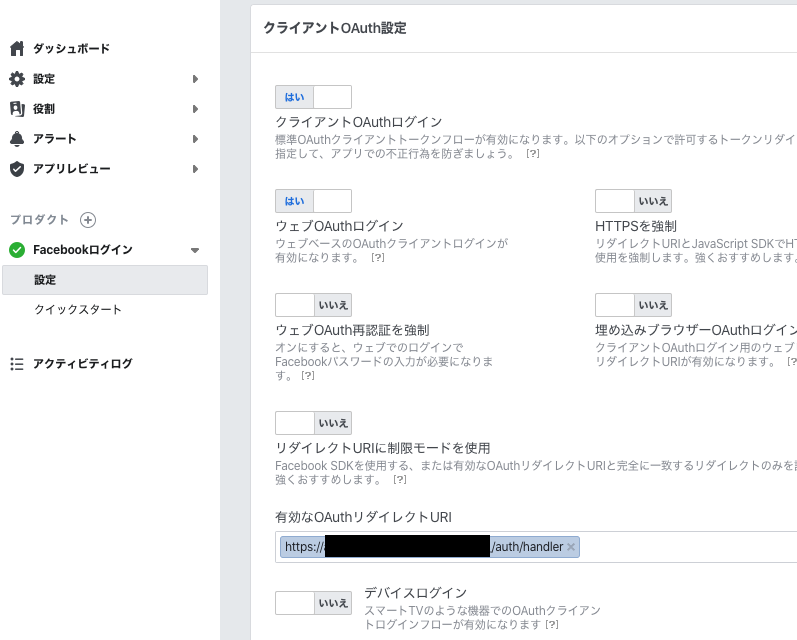
以上で設定は完了です。
Signin
自作のアプリケーションからSigninします

Facebookログインを試みると、
よく見るFacebookの承認画面が表示され、ログインを押すと、無事アプリケーションにログインできるようになりました。

注意すべきところ
接続元の環境がhttp
ローカルで開発しているので、http://localhost/ で確認していたのですが、httpでFacebookログインを試みると
Facebook側で以下のようなアラートが出て、invalid_request
無視して進めたところ認証エラーが。
Error getting verification code from facebook.com response: error=invalid_request&error_code=191&error_description
というエラーが表示されるようになりました。
その対策としてFirebase Hostingへdeployして、httpsで接続できるようにした上でFacebookとの接続をするようにしました。
メールアドレスの重複
既に他のソーシャルアカウントでログインした後に、Facebookアカウントでログインを試みるとエラーが。。
An account already exists with the same email address but different sign-in credentials. Sign in using a provider associated with this email address
どうやらFirebaseのデフォルトの動きとしてソーシャルアカウントに登録したメールアドレスが、他のソーシャルアカウントで使っている場合、「既に登録してある」と見なされアカウント作成できないようです。
もちろんFirebaseで承認したアカウントを削除することで、Facebookアカウントでログインできるようになりました。
しかし、やはりユーザーによっては複数ソーシャルアカウントが同一メールアドレスで登録している人も少なくありません。
設定変更画面から複数メールアドレスの登録を許可させることができます。

デフォルトでは上段が選択されていますが、下の「複数のアカウントを作成できるようにする」を選択します。
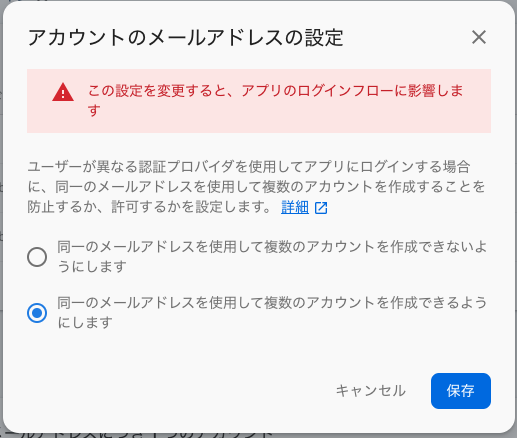
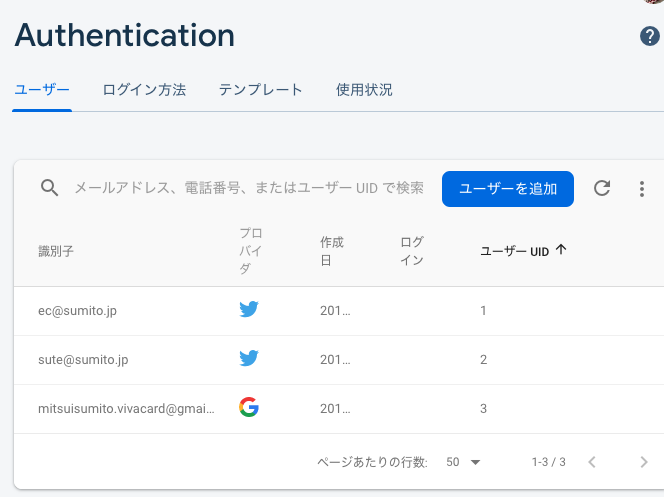
Google認証に加え、Facebookアカウントでもログインできるようになりました。
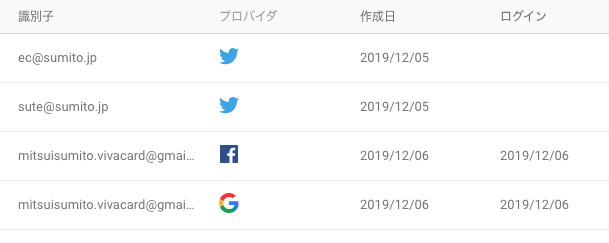
登録アカウントは以下の通り。
Firebaseはシンプルな認証機能を提供してくれるので、これからアプリケーションを作っていくという場合は最適な選択肢になるのではないでしょうか。








![mmap() failed: [12] Cannot allocate memory](https://sumito.jp/wp-content/uploads/2018/07/light-bulb-3535435_640.jpg)
