問題発生
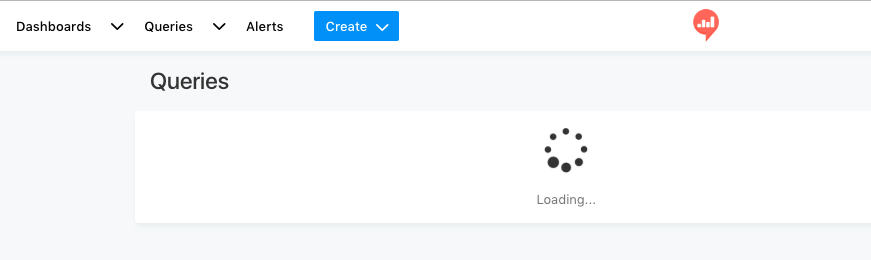
QueriesがLoadingのままで、Query一覧が表示されない
redash_serverコンテナには以下のログが吐かれていた
[2018-10-10 12:48:45,419][PID:14][ERROR][redash] Exception on /api/queries [GET]
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/flask/app.py", line 1639, in full_dispatch_request
rv = self.dispatch_request()
File "/usr/local/lib/python2.7/dist-packages/flask/app.py", line 1625, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/usr/local/lib/python2.7/dist-packages/flask_restful/__init__.py", line 477, in wrapper
resp = resource(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/flask_login/utils.py", line 228, in decorated_view
return func(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/flask/views.py", line 84, in view
return self.dispatch_request(*args, **kwargs)
File "/app/redash/handlers/base.py", line 31, in dispatch_request
return super(BaseResource, self).dispatch_request(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/flask_restful/__init__.py", line 587, in dispatch_request
resp = meth(*args, **kwargs)
File "/app/redash/permissions.py", line 48, in decorated
return fn(*args, **kwargs)
File "/app/redash/handlers/queries.py", line 197, in get
with_last_modified_by=False
File "/app/redash/handlers/base.py", line 106, in paginate
items = serializer(results.items, **kwargs).serialize()
File "/app/redash/serializers.py", line 75, in serialize
result = [serialize_query(query, **self.options) for query in self.object_or_list]
File "/app/redash/serializers.py", line 105, in serialize_query
d['user'] = query.user.to_dict()
AttributeError: 'NoneType' object has no attribute 'to_dict'
解決へのアプローチ
とりあえずググる。前例が見つからない。
twitterで騒ぐ。知ってる人いるかも。
すぐに見つからない。
redashのフォーラムに聞いた。
https://discuss.redash.io/t/when-open-queries-all-queries-always-loading/2449
redashの生みの親、arikfr がコメントをくれた

https://discuss.redash.io/t/when-open-queries-all-queries-always-loading/2449/2?u=gitsumito
あ!確かに消しました。
そういえばやったこと
この画面にたどり着く前、redashユーザーの作成を行なった。
docker exec -it redash_server_1 ./manage.py users create taro@sumito.jp taro
manage.pyを使い、ユーザーの追加した。
ちなみにこのmanage.pyを使い、ユーザの追加・削除することは随分前のversionから利用可能で、このコマンドを用いた管理方法は @kakakakakku 氏のブログが非常にわかりやすい
ただ、redash version 5.0でredashユーザーの作成を行うと(昔のバージョンもかも)、既に登録されているユーザでも新しく登録できてしまう。
つまりデータベースに二重に登録されてしまう状態だった。
この状態で作成したユーザでloginしようとすると、Internal Server Errorになりログインできなくなる。
仕方なくユーザーを削除することにした
docker exec -it redash_server_1 ./manage.py users delete taro@sumito.jp
Successfully。削除できた。
再度ユーザの作成を行なうと、無事作成したユーザでredashにログインできるようになった。
めでたし、めでたし。と思ったが、今回の問題
redashでALL Queriesを選択すると “Loading…” のままで変わらない
という問題に繋がったようだ。
解決方法
postgresのコンテナにログインし、userid周りを調整
docker exec -it redash_postgres_1 /bin/bash
psql -U postgres postgres
redashのユーザ情報が格納されているusersテーブルでidを確認する
postgres=# select * from users order by id desc;
updated_at | created_at | id | org_id | name | email | password_hash | groups | api_key | profile_image_url | disabled_at
-------------------------------+-------------------------------+----+--------+--------------------+-----------------------------------------+--------------------------------------------------------------------------------------------------------------------------+-----------+------------------------------------------+-------------------+-------------------------------
(skip)
2018-08-30 06:48:30.812508+00 | 2018-08-30 06:40:15.029328+00 | 51 | 1 | *** | gomes@sumito.jp | *** | {2,5} | *** | |
2018-10-09 08:18:34.331088+00 | 2018-10-09 08:17:20.97545+00 | 55 | 1 | taro | taro@sumito.jp | *** | {2,5} | *** | |
2018-10-09 08:18:37.220691+00 | 2018-10-09 08:18:00.078037+00 | 56 | 1 | jiro | jiro@sumito.jp | *** | {2,5} | *** |
id 52~54 が欠番していることがわかる。
これが自分が削除したユーザのID。
まずはid 52~56のeventテーブルから全ての履歴を削除した
SELECT * FROM events WHERE user_id = 52;
DELETE FROM events WHERE user_id = 52;
SELECT * FROM events WHERE user_id = 53;
DELETE FROM events WHERE user_id = 53;
SELECT * FROM events WHERE user_id = 54;
DELETE FROM events WHERE user_id = 54;
SELECT * FROM events WHERE user_id = 55;
DELETE FROM events WHERE user_id = 55;
SELECT * FROM events WHERE user_id = 56;
DELETE FROM events WHERE user_id = 56;
これでイベントが全て削除された。
usersテーブルのid 55,56 を 52,53 に変更した
update users set id = 52 where email = 'taro@sumito.jp';
update users set id = 53 where email = 'jiro@sumito.jp';
その後、user idのインクリメント部分を管理しているusers_id_seq
を56 から 53に変更した。
ALTER SEQUENCE users_id_seq RESTART WITH 53;
対応はこれだけ、
無事問題が解決した。
最後に
CLIを見直すことを示唆してくれた。

今後のversion upが楽しみ。