はじめに Introduction
macでpip installを行った際、以下のようなエラーが出てinstallができなかった。
When pip install was performed on mac, the following error occurred and installation failed.
$ pip3 install numpy
pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available.
Collecting numpy
Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not available.")': /simple/numpy/
Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not available.")': /simple/numpy/
Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not available.")': /simple/numpy/
Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not available.")': /simple/numpy/
Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not available.")': /simple/numpy/
Could not fetch URL https://pypi.org/simple/numpy/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/numpy/ (Caused by SSLError("Can't connect to HTTPS URL because the SSL module is not available.")) - skipping
Could not find a version that satisfies the requirement numpy (from versions: )
No matching distribution found for numpy
pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available.
Could not fetch URL https://pypi.org/simple/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/pip/ (Caused by SSLError("Can't connect to HTTPS URL because the SSL module is not available.")) - skipping
原因 Cause of the problem
SSL通信ができない?
Can’t SSL communication?
対処 countermeasure
admin権限を持つアカウントで同様のコマンドを実行したところ、無事インストールができた。 おそらく権限周りの問題が根幹にあるようだ。
When I executed the same command with an account with admin privileges, the installation was successful. Perhaps there is a problem around authority.


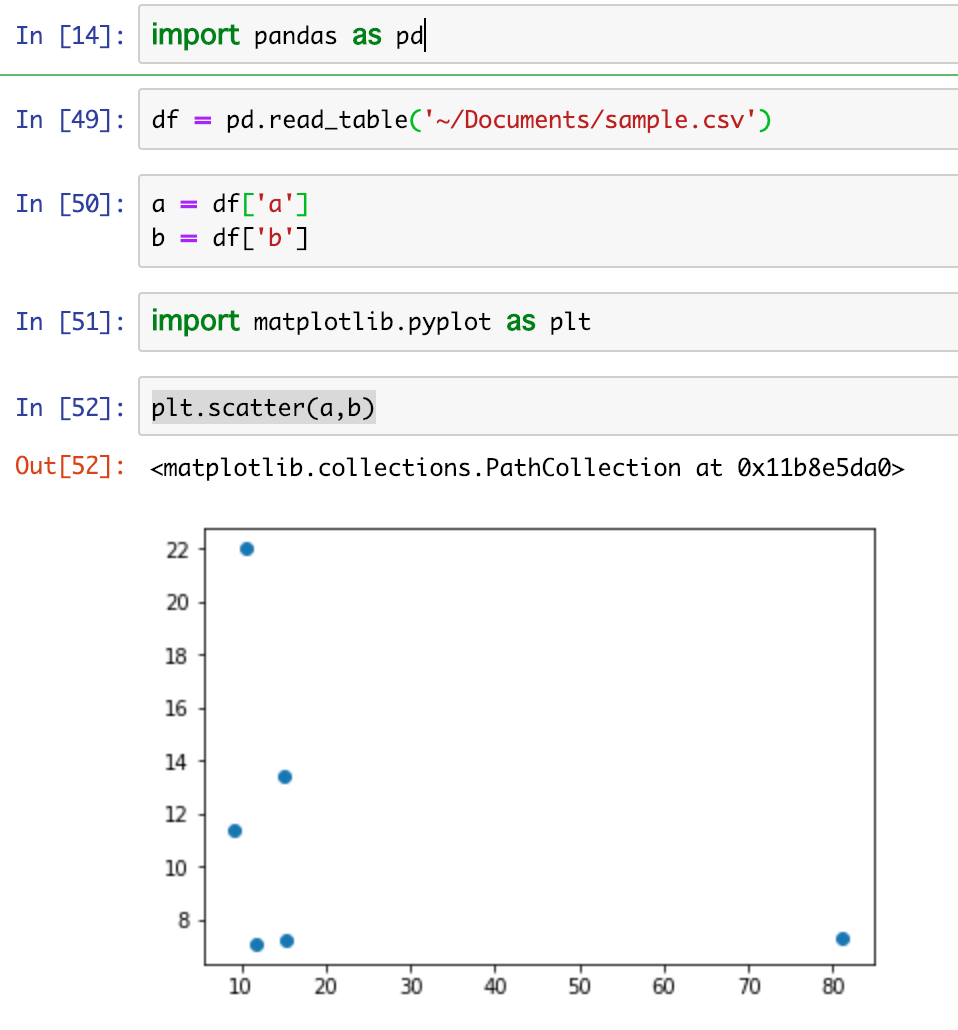
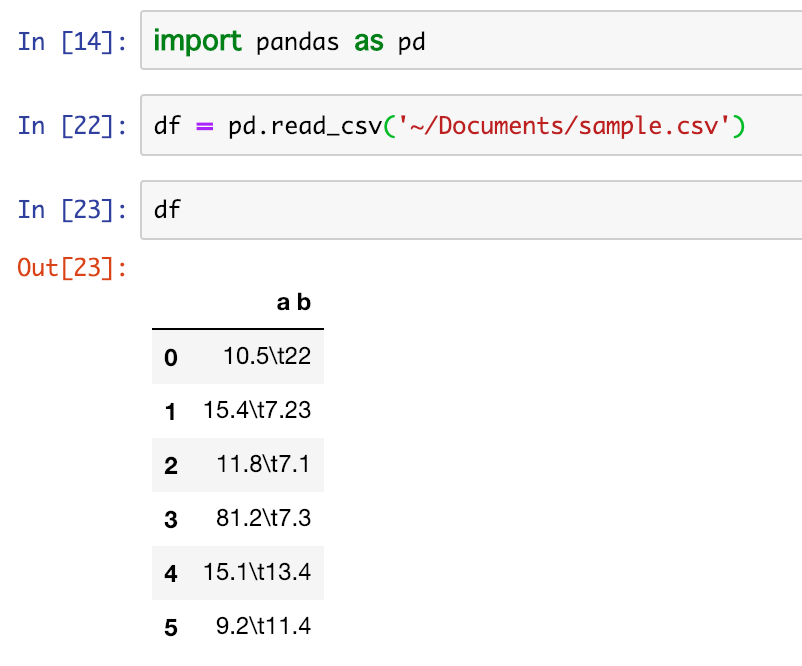 ちなみに読み込んだデータはこちら
ちなみに読み込んだデータはこちら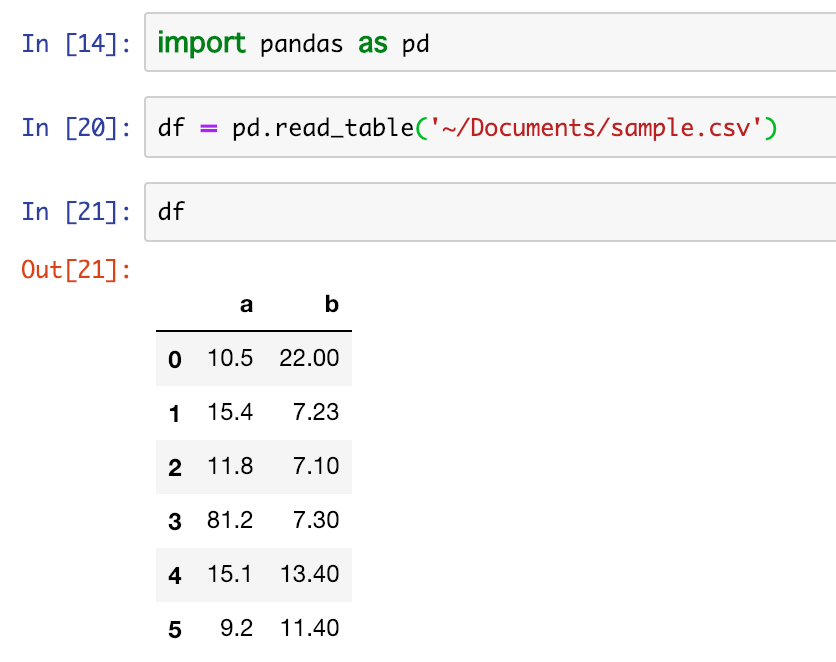 また、表示する件数を絞りたい場合はhead()を利用する
また、表示する件数を絞りたい場合はhead()を利用する 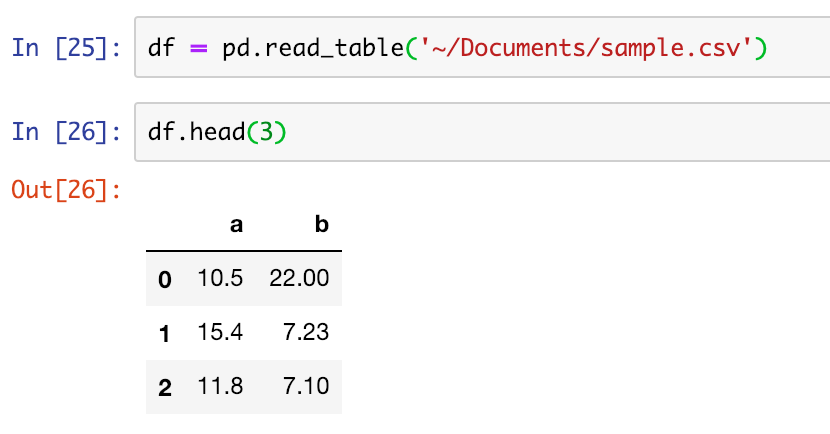 3を引数に渡すことで表示件数を3件に絞ることが可能になる。
3を引数に渡すことで表示件数を3件に絞ることが可能になる。

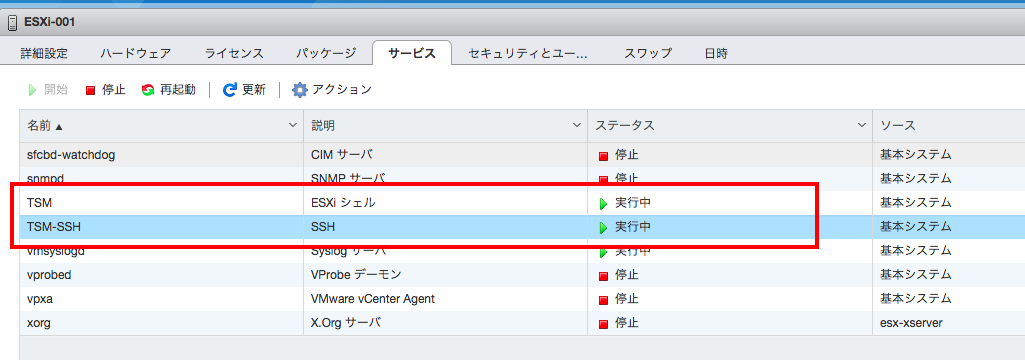 ESXiシェルとSSHがデフォルトで停止されている。まずはこれを有効にする
ESXiシェルとSSHがデフォルトで停止されている。まずはこれを有効にする