Notice!
以下の記事で redash のみで行う方法をまとめております。
こちらの記事をご覧ください。
https://tsukada.sumito.jp/2020/02/28/redash-api-query-parameter/
はじめに(本記事はサードパーティを利用した方法です)
redashはとても便利だが、パラメータを動的に変えてクエリを投げる様な事はオフィシャルにはできない
しかし、それもサードパーティを利用し、少し手を加える事で実現可能になる。
検証環境の構築
サンプルをダウンロード
サンプルのredashと、適当なデータが入ったmysqlをダウンロード
git clone https://github.com/GitSumito/redash-blue
セットアップ
docker-compose run --rm server create_db docker-compose up
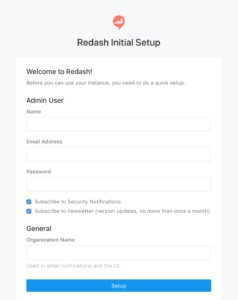
http://localhost/setup
へ接続するとセットアップ画面が表示されるので入力する
ログインすると、右上のメニューから Edit Profile を選択する
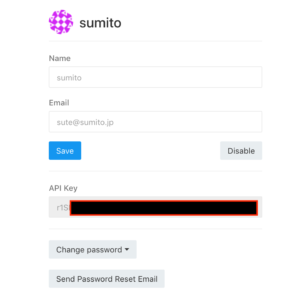
API keyが表示されるのでひかえる
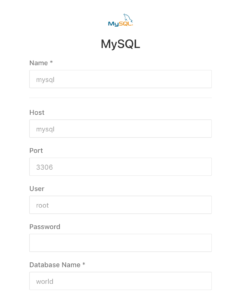
データソースにmysqlを追加する
設定は以下の通り
この時、保存した際のURLを確認する

/data_sources/1 とある。
これがデータソース番号となる。今回登録したデータソースは1番ということがこれでわかる。
クエリを書く
select * from city where CountryCode = "{{code}}"
このクエリを書くと、下にテキストボックスが表示される

これでExecuteボタンを押すと、where CountryCode = “JPN” が実施される
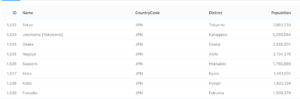
クエリを保存すると、以下の様なURLになっている

後ろにパラメータがついているがそれは無視すると、クエリ番号1番となっていることがわかる。
https://github.com/mozilla/redash_client
mozillaでredash clientというものが存在している。
これを ariarijp さんが改修してくれていた。神!
(今現在masterに取りこめられていないが、非常に便利な機能だ)
差分が公開されているので、これを元にオリジナルのmozillaを一部改修する
https://github.com/mozilla/redash_client/pull/70/files#diff-80f7450d3a8b47a2d0a622873d1a67fe
これにより、動的クエリを受け付けることができるようになる
from pprint import pprint
import os
import pystache
from redash_client.client import RedashClient
api_key = os.environ["REDASH_API_KEY"]
client = RedashClient(api_key)
client.BASE_URL = 'http://127.0.0.1/'
client.API_BASE_URL = client.BASE_URL + 'api/'
query = client.get_query(1)
sql = pystache.render(query['query'], {
'code': 'JPN',
})
result = client.get_query_results(sql, query['data_source_id'])
pprint(result, width=160)
その後、環境変数に
REDASH_API_KEY
をセットする
export REDASH_API_KEY=*********************
実行結果
$ python3 mozilla.py
[{'CountryCode': 'JPN', 'District': 'Tokyo-to', 'ID': 1532, 'Name': 'Tokyo', 'Population': 7980230},
{'CountryCode': 'JPN', 'District': 'Kanagawa', 'ID': 1533, 'Name': 'Jokohama [Yokohama]', 'Population': 3339594},
{'CountryCode': 'JPN', 'District': 'Osaka', 'ID': 1534, 'Name': 'Osaka', 'Population': 2595674},
{'CountryCode': 'JPN', 'District': 'Aichi', 'ID': 1535, 'Name': 'Nagoya', 'Population': 2154376},
{'CountryCode': 'JPN', 'District': 'Hokkaido', 'ID': 1536, 'Name': 'Sapporo', 'Population': 1790886},
{'CountryCode': 'JPN', 'District': 'Kyoto', 'ID': 1537, 'Name': 'Kioto', 'Population': 1461974},
{'CountryCode': 'JPN', 'District': 'Hyogo', 'ID': 1538, 'Name': 'Kobe', 'Population': 1425139},
scriptのcodeを変えて実行
$ python3 mozilla.py
[{'CountryCode': 'USA', 'District': 'New York', 'ID': 3793, 'Name': 'New York', 'Population': 8008278},
{'CountryCode': 'USA', 'District': 'California', 'ID': 3794, 'Name': 'Los Angeles', 'Population': 3694820},
{'CountryCode': 'USA', 'District': 'Illinois', 'ID': 3795, 'Name': 'Chicago', 'Population': 2896016},
{'CountryCode': 'USA', 'District': 'Texas', 'ID': 3796, 'Name': 'Houston', 'Population': 1953631},
{'CountryCode': 'USA', 'District': 'Pennsylvania', 'ID': 3797, 'Name': 'Philadelphia', 'Population': 1517550},
{'CountryCode': 'USA', 'District': 'Arizona', 'ID': 3798, 'Name': 'Phoenix', 'Population': 1321045},
取得結果が変わった。
色々活用できる場がありそうだ。