はじめに
Googleがトレーニング済みモデルとして提供している自然言語処理(Natural Language Processing)を使うことで、文字を元に感情分析、エンティティ分析、エンティティ感情分析、コンテンツ分類、構文分析などの自然言語理解の機能がAPI経由で利用できるとのこと。
Cloud Natural Language APIで、どのような結果を得る事ができるか試してみた。
どのような事ができるのか
公式ドキュメントでは以下の通り記載されている
https://cloud.google.com/sdk/gcloud/reference/ml/language/
analyze-entitiesUse Google Cloud Natural Language API to identify entities in text.
analyze-entity-sentimentUse Google Cloud Natural Language API to identify entity-level sentiment.
analyze-sentimentUse Google Cloud Natural Language API to identify sentiments in a text.
analyze-syntaxUse Google Cloud Natural Language API to identify linguistic information.
classify-textClassifies input document into categories.
上から
- エンティティ分析
- エンティティ感情分析
- 感情分析
- 構文解析
- コンテンツ分類
だ。ひとつひとつ試していったので、実行コマンドと結果とともに解説していく。
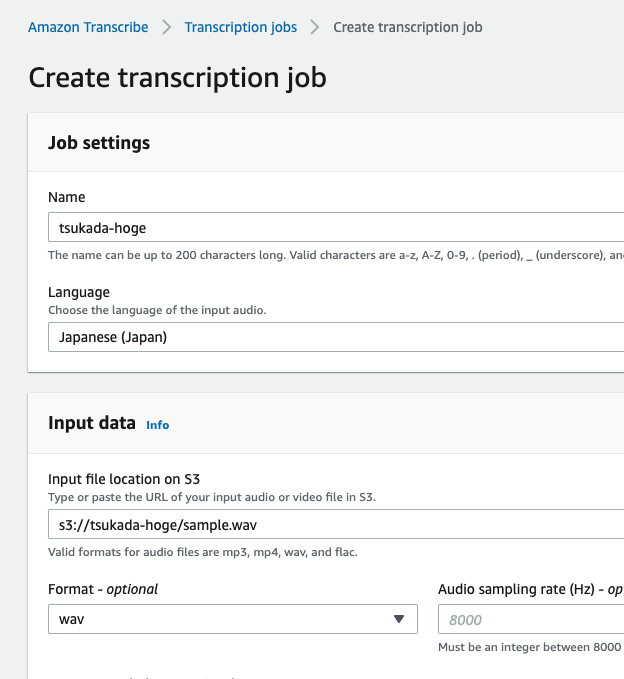
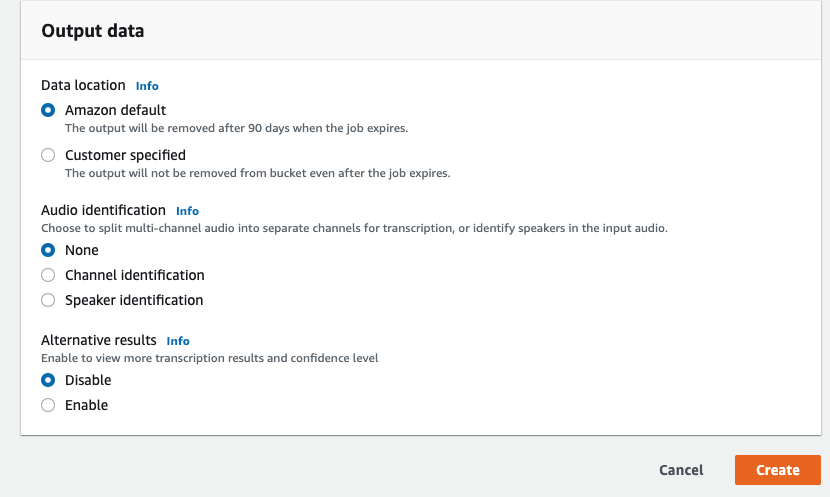
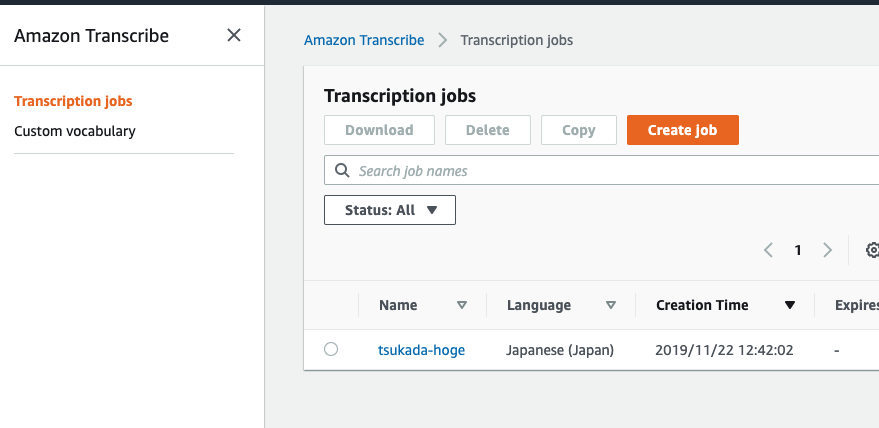
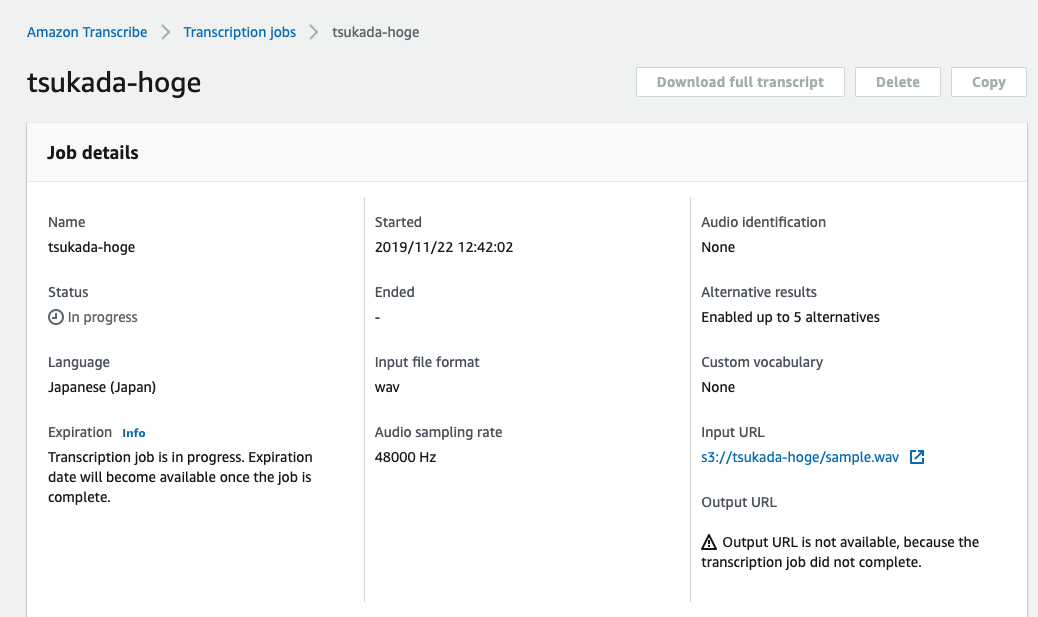
解析対象
著作権フリーのドキュメントを解析対象とした。
learningenglish.voanews.comというサイトは著作権フリーでテキスト、MP3を公開しているとのことだったので、今回はそれをコンテンツを利用することにした。
その中でも「我々のコンテンツは著作権フリーですよ」と記載されているページを解析することにした。
https://learningenglish.voanews.com/p/6861.html
https://learningenglish.voanews.com/p/6861.html
Requesting usage of VOA Learning English content
Learning English texts, MP3s and videos are in the public domain. You are allowed to reprint them for educational and commercial purposes, with credit to learningenglish.voanews.com. VOA photos are also in the public domain. However, photos and video images from news agencies such as AP and Reuters are copyrighted, so you are not allowed to republish them.
If you are requesting one-time use of VOA Learning English content, please fill out the information in this form and we will respond to you as soon as possible. For repeat use, please see the Content Usage FAQs on the page.
High-resolution audio and video files can be downloaded for free through USAGM Direct an online service providing original multimedia content from Voice of America for publication across all platforms: online, mobile, print and broadcast. Access to USAGM Direct requires user registration. If you have any questions about our policies, or to let us know that you plan to use our materials, write to learningenglish@voanews.com.
各種コマンドを実施した後、リダイレクトとしてテキストに出力させ、結果が膨大なので、上位100桁のみ表示させる。
なお、Natural Language APIの基本について書かれているドキュメントはこちら。
https://cloud.google.com/natural-language/docs/basics?hl=ja
エンティティ分析
テキストデータからエンティティ(人、組織、場所、イベント、商品、メディアなど)を特定できるようだ。
実施コマンド
gcloud ml language analyze-entities --content-file=/tmp/voa.original > /tmp/voa.analyze-entities
結果
# head -n100 /tmp/voa.analyze-entities
{
"entities": [
{
"mentions": [
{
"text": {
"beginOffset": 90,
"content": "content"
},
"type": "COMMON"
},
{
"text": {
"beginOffset": 518,
"content": "content"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "content",
"salience": 0.1703016,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 60,
"content": "usage"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "usage",
"salience": 0.077866085,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 132,
"content": "videos"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "videos",
"salience": 0.07223342,
"type": "WORK_OF_ART"
},
{
"mentions": [
{
"text": {
"beginOffset": 0,
"content": "https://learningenglish.voanews.com/p/6861.html"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 253,
"content": "learningenglish.voanews.com"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 282,
"content": "VOA"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 831,
"content": "Voice of America"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 1083,
"content": "learningenglish@voanews.com"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/0q0r9",
"wikipedia_url": "https://en.wikipedia.org/wiki/Voice_of_America"
},
"name": "https://learningenglish.voanews.com/p/6861.html",
"salience": 0.07165857,
"type": "OTHER"
},
結果の見方は以下の通り。
name解析対象の文字列
beginOffset: 指定したテキスト内の文の開始位置を表す(0 から始まる)文字オフセットを示します。このオフセットは、リクエストで渡した encodingType を使用して計算される。
salienceドキュメントのテキスト全体に対するこのエンティティの重要性または関連性を示します。情報の取得や要約の際にエンティティを優先するのに役立ちます。スコアが 0.0 に近いほど重要性が低くなり、1.0 に近いほど重要性が高くなる。
typeドキュメントの種類(HTML または PLAIN_TEXT)などが書かれる。
metadatawikipediaにリンクがあればwikipedia_urlに書かれる。midはGoogle Knowledge GraphのMID(Machine-generated Identifier)が格納される
エンティティ感情分析
エンティティ分析と感情分析の両方を組み合わせたものであり、テキスト内でエンティティについて表現された感情(ポジティブかネガティブか)の特定ができるようだ
実施コマンド
gcloud ml language analyze-entity-sentiment --content-file=/tmp/voa.original > /tmp/voa.analyze-entity-sentiment
結果
# head -n100 /tmp/voa.analyze-entity-sentiment
{
"entities": [
{
"mentions": [
{
"sentiment": {
"magnitude": 0.2,
"score": 0.2
},
"text": {
"beginOffset": 90,
"content": "content"
},
"type": "COMMON"
},
{
"sentiment": {
"magnitude": 0.1,
"score": 0.1
},
"text": {
"beginOffset": 518,
"content": "content"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "content",
"salience": 0.1703016,
"sentiment": {
"magnitude": 0.3,
"score": 0.1
},
"type": "OTHER"
},
{
"mentions": [
{
"sentiment": {
"magnitude": 0.5,
"score": 0.5
},
"text": {
"beginOffset": 60,
"content": "usage"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "usage",
"salience": 0.077866085,
"sentiment": {
"magnitude": 0.5,
"score": 0.5
},
"type": "OTHER"
},
{
"mentions": [
{
"sentiment": {
"magnitude": 0.4,
"score": 0.4
},
"text": {
"beginOffset": 132,
"content": "videos"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "videos",
"salience": 0.07223342,
"sentiment": {
"magnitude": 0.4,
"score": 0.4
},
"type": "WORK_OF_ART"
},
{
"mentions": [
{
"sentiment": {
"magnitude": 0.0,
"score": 0.0
},
"text": {
"beginOffset": 0,
"content": "https://learningenglish.voanews.com/p/6861.html"
},
"type": "PROPER"
},
{
"sentiment": {
"magnitude": 0.1,
"score": 0.1
},
magnitude: 指定したテキストの全体的な感情の強度(ポジティブとネガティブの両方)が 0.0~+inf の値で示されるscore と違って magnitude は正規化されていないため、テキスト内で感情(ポジティブとネガティブの両方)が表現されるたびにテキストの magnitude の値が増加
と、公式にはあるが、ドキュメントは正直よくわからないが、以下の表は非常にわかりやすかった。
| 感情 |
サンプル値 |
| 明らかにポジティブ* |
"score": 0.8、"magnitude": 3.0 |
| 明らかにネガティブ* |
"score": -0.6、"magnitude": 4.0 |
| ニュートラル |
"score": 0.1、"magnitude": 0.0 |
| 混合 |
"score": 0.0、"magnitude": 4.0 |
感情分析
指定されたテキストを調べて、そのテキストの背景にある感情的な考え方を分析することができる。
実施コマンド
gcloud ml language analyze-sentiment --content-file=/tmp/voa.original > /tmp/voa.analyze-sentiment
結果
# head -n100 /tmp/voa.analyze-sentiment
{
"documentSentiment": {
"magnitude": 4.6,
"score": 0.2
},
"language": "en",
"sentences": [
{
"sentiment": {
"magnitude": 0.0,
"score": 0.0
},
"text": {
"beginOffset": 0,
"content": "https://learningenglish.voanews.com/p/6861.html"
}
},
{
"sentiment": {
"magnitude": 0.8,
"score": 0.8
},
"text": {
"beginOffset": 49,
"content": "Requesting usage of VOA Learning English content"
}
},
{
"sentiment": {
"magnitude": 0.8,
"score": 0.8
},
"text": {
"beginOffset": 99,
"content": "Learning English texts, MP3s and videos are in the public domain."
}
},
{
"sentiment": {
"magnitude": 0.0,
"score": 0.0
},
"text": {
"beginOffset": 165,
"content": "You are allowed to reprint them for educational and commercial purposes, with credit to learningenglish.voanews.com."
}
},
{
"sentiment": {
"magnitude": 0.1,
"score": 0.1
},
"text": {
"beginOffset": 282,
"content": "VOA photos are also in the public domain."
}
},
{
"sentiment": {
"magnitude": 0.4,
"score": -0.4
},
"text": {
"beginOffset": 324,
"content": "However, photos and video images from news agencies such as AP and Reuters are copyrighted, so you are not allowed to republish them."
}
},
{
"sentiment": {
"magnitude": 0.7,
"score": 0.7
},
"text": {
"beginOffset": 459,
"content": "If you are requesting one-time use of VOA Learning English content, please fill out the information in this form and we will respond to you as soon as possible."
}
},
{
"sentiment": {
"magnitude": 0.2,
"score": -0.2
},
"text": {
"beginOffset": 620,
"content": "For repeat use, please see the Content Usage FAQs on the page."
}
},
{
"sentiment": {
"magnitude": 0.3,
"score": 0.3
},
"text": {
"beginOffset": 684,
"content": "High-resolution audio and video files can be downloaded for free through USAGM Direct an online service providing original multimedia content from Voice of America for publication across all platforms: online, mobile, print and broadcast."
}
},
{
"sentiment": {
"magnitude": 0.3,
各種項目は今までに説明したものがメイン。大きな特徴はcontentが単語ではなく、文(センテンス)になっているということ。センテンス単位でmagnitudeや、scoreが算出されている。
そのため、文を通して感情を数値として読み取る事ができる。
コンテンツ分類
ドキュメントを分析し、ドキュメント内で見つかったテキストに適用されるコンテンツカテゴリのリストを返す事ができる
実施コマンド
gcloud ml language classify-text --content-file=/tmp/voa.original > /tmp/voa.classify-text
結果
# head -n100 /tmp/voa.classify-text
{
"categories": [
{
"confidence": 0.81,
"name": "/Reference/Language Resources/Foreign Language Resources"
}
]
}
“リファレンス/言語リソース/外国語リソース”
外国語コンテンツのリファレンスということが、なんとなくわかる。
構文解析
指定されたテキストを一連の文とトークン(通常は単語)に分解して、それらのトークンに関する言語情報を提供する
実行コマンド
gcloud ml language analyze-syntax --content-file=/tmp/voa.original > /tmp/voa.analyze-syntax
結果
# head -n200 /tmp/voa.analyze-syntax
{
"language": "en",
"sentences": [
{
"text": {
"beginOffset": 0,
"content": "https://learningenglish.voanews.com/p/6861.html"
}
},
{
"text": {
"beginOffset": 49,
"content": "Requesting usage of VOA Learning English content"
}
},
{
"text": {
"beginOffset": 99,
"content": "Learning English texts, MP3s and videos are in the public domain."
}
},
{
"text": {
"beginOffset": 165,
"content": "You are allowed to reprint them for educational and commercial purposes, with credit to learningenglish.voanews.com."
}
},
{
"text": {
"beginOffset": 282,
"content": "VOA photos are also in the public domain."
}
},
{
"text": {
"beginOffset": 324,
"content": "However, photos and video images from news agencies such as AP and Reuters are copyrighted, so you are not allowed to republish them."
}
},
{
"text": {
"beginOffset": 459,
"content": "If you are requesting one-time use of VOA Learning English content, please fill out the information in this form and we will respond to you as soon as possible."
}
},
{
"text": {
"beginOffset": 620,
"content": "For repeat use, please see the Content Usage FAQs on the page."
}
},
{
"text": {
"beginOffset": 684,
"content": "High-resolution audio and video files can be downloaded for free through USAGM Direct an online service providing original multimedia content from Voice of America for publication across all platforms: online, mobile, print and broadcast."
}
},
{
"text": {
"beginOffset": 923,
"content": "Access to USAGM Direct requires user registration."
}
},
{
"text": {
"beginOffset": 974,
"content": "If you have any questions about our policies, or to let us know that you plan to use our materials, write to learningenglish@voanews.com."
}
}
],
"tokens": [
{
"dependencyEdge": {
"headTokenIndex": 0,
"label": "ROOT"
},
"lemma": "https://learningenglish.voanews.com/p/6861.html",
"partOfSpeech": {
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tag": "X",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"text": {
"beginOffset": 0,
"content": "https://learningenglish.voanews.com/p/6861.html"
}
},
{
"dependencyEdge": {
"headTokenIndex": 2,
"label": "AMOD"
},
"lemma": "request",
"partOfSpeech": {
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tag": "VERB",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"text": {
"beginOffset": 49,
"content": "Requesting"
}
},
{
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "usage",
"partOfSpeech": {
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "SINGULAR",
"person": "PERSON_UNKNOWN",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"text": {
"beginOffset": 60,
"content": "usage"
}
},
{
"dependencyEdge": {
"headTokenIndex": 2,
"label": "PREP"
},
"lemma": "of",
"partOfSpeech": {
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tag": "ADP",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"text": {
"beginOffset": 66,
"content": "of"
}
},
{
"dependencyEdge": {
"headTokenIndex": 6,
"label": "NN"
},
"lemma": "VOA",
"partOfSpeech": {
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "SINGULAR",
"person": "PERSON_UNKNOWN",
"proper": "PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"text": {
"beginOffset": 69,
"content": "VOA"
}
},
{
"dependencyEdge": {
"headTokenIndex": 6,
"label": "NN"
文とトークンが抽出され、それらの文(sentences)と中盤以降にトークン(tokens)を含むレスポンスが返される。
tag�はNOUN(名詞)、VERB(動詞)、ADJ(形容詞)などがわかる。
まとめ
GCPが使えるようになっていれば非常に簡単にCloud Natural Language API を試す事ができ、使い方によっては非常に有益な解析ができそうだ。







![mmap() failed: [12] Cannot allocate memory](https://sumito.jp/wp-content/uploads/2018/07/light-bulb-3535435_640.jpg)