はじめに
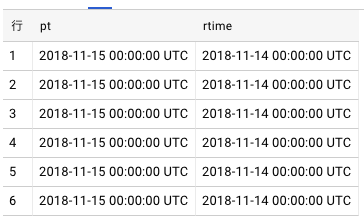
BigQueryにbqコマンドでテーブル作成・データ投入・スキーマ変更する。 ネストされたデータも扱いたいので、今回はjsonファイルを読み込むようにする CSVは現段階でネストされたデータのimportをサポートされていない
CSV ファイルはネストされたデータや繰り返しデータに対応していません。
https://cloud.google.com/bigquery/docs/loading-data-cloud-storage-csv ちょうどいいサンプルデータ( https://gist.github.com/isdyy/5072792 )を置いてくださる方がいたので、それを拝借。
準備
https://gist.github.com/isdyy/5072792 にあるように2つのデータを用意する。1つはスキーマ。もう1つはデータ
- スキーマ
[
{
"name": "kind",
"type": "string"
},
{
"name": "fullName",
"type": "string"
},
{
"name": "age",
"type": "integer"
},
{
"name": "gender",
"type": "string"
},
{
"name": "citiesLived",
"type": "record",
"mode": "repeated",
"fields": [
{
"name": "place",
"type": "string"
},
{
"name": "numberOfYears",
"type": "integer"
}
]
},
{
"name": "note",
"type": "string"
}
]
- データ
{"gender": "Male", "fullName": "John Doe", "age": 22, "citiesLived": [{"numberOfYears": 5, "place": "Seattle"}, {"numberOfYears": 6, "place": "Stockholm"}], "kind": "person"}
{"gender": "Female", "fullName": "Jane Austen", "age": 24, "citiesLived": [{"numberOfYears": 2, "place": "Los Angeles"}, {"numberOfYears": 2, "place": "Tokyo"}], "kind": "person"}
{"note": "with newline (\\n)", "kind": "person", "gender": "Male", "age": 30, "fullName": "newline", "citiesLived": [{"place": "Shinjuku-ku,\nTokyo"}]}
{"note": "with tab (\\t)", "age": 30, "fullName": "tab", "citiesLived": [{"place": "Shinjuku-ku,\tTokyo"}], "kind": "person"}
{"note": "japanese / unicode escape sequence", "gender": "Female", "citiesLived": [{"place": "\u6a2a\u6d5c\u5e02"}], "fullName": "\u6a2a\u6d5c \u82b1\u5b50 (1)", "kind": "person"}
{"note": "japanese / raw utf-8", "gender": "Female", "citiesLived": [{"place": "横浜市"}], "fullName": "横浜 花子 (2)", "kind": "person"}
{"note": "double-quoted string", "fullName": "\"quoted\"", "kind": "person"}
テーブルのみ作成
# bq mk --table logs.sample nested01.fields.json
Table '****:logs.sample' successfully created.
ブラウザ上で以下の通り作成されている 
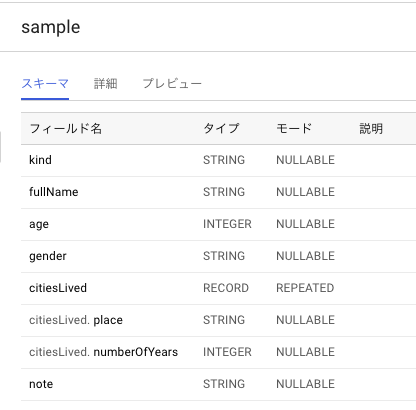 また、bq showコマンドでスキーマを確認できる
また、bq showコマンドでスキーマを確認できる
# bq show logs.sample
Table ****:logs.sample
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Labels
----------------- ----------------------------------- ------------ ------------- ------------ ------------------- --------
19 Nov 21:09:54 |- kind: string 0 0
|- fullName: string
|- age: integer
|- gender: string
+- citiesLived: record (repeated)
| |- place: string
| |- numberOfYears: integer
|- note: string
データの投入
# bq load --source_format=NEWLINE_DELIMITED_JSON logs.sample nested01.data.json
Upload complete.
Waiting on bqjob_r4b711f3cb6f6854b_000001672be52e12_1 ... (0s) Current status: DONE
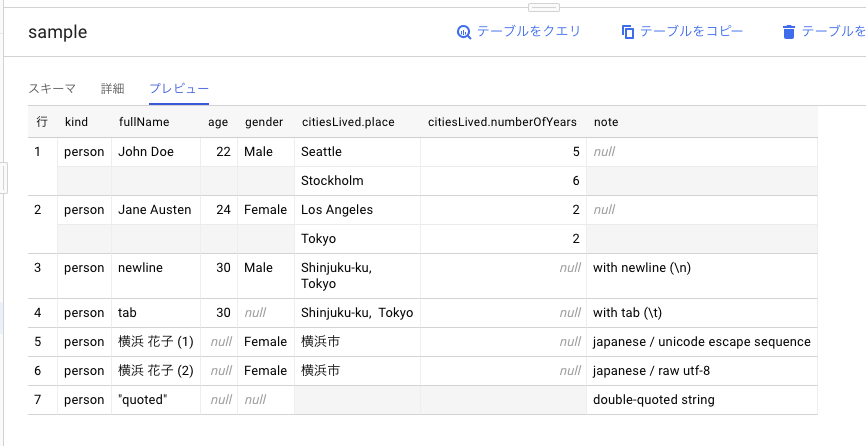 無事投入された。適切にネストもされている。
無事投入された。適切にネストもされている。
テーブル作成+データ投入
スキーマ作成と同時に、データの投入も可能
# bq load --source_format=NEWLINE_DELIMITED_JSON logs.sample nested01.data.json nested01.fields.json
Upload complete.
Waiting on bqjob_r49704f78c779ebd5_000001672bd96baa_1 ... (0s) Current status: DONE
もちろん結果は同じ
データのみをつかって、テーブルを自動作成
“` –autodetect “` オプションを使う。
# bq load --source_format=NEWLINE_DELIMITED_JSON --autodetect logs.sample nested01.data.json
Upload complete.
Waiting on bqjob_r49704f78c779ebd115_00001672bd96baa_1 ... (0s) Current status: DONE
スキーマを変更する
nested01.fields.jsonを以下の通り変更
[
{
"name": "kind",
"type": "string"
},
{
"name": "fullName",
"type": "string"
},
{
"name": "age",
"type": "integer"
},
{
"name": "gender",
"type": "string"
},
{
"name": "country",
"type": "string"
},
{
"name": "company",
"type": "string"
},
{
"name": "citiesLived",
"type": "record",
"mode": "repeated",
"fields": [
{
"name": "place",
"type": "string"
},
{
"name": "numberOfYears",
"type": "integer"
}
]
},
{
"name": "note",
"type": "string"
}
]
# bq update logs.sample nested01.fields.json
Table '****:logs.sample' successfully updated.
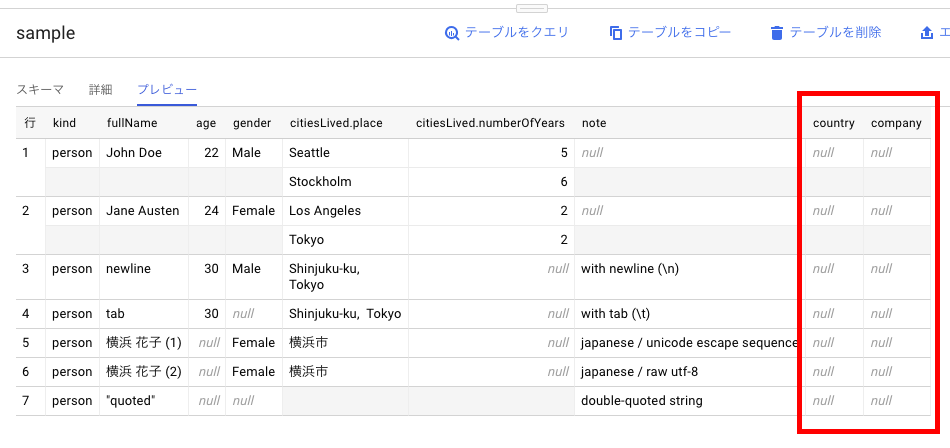 スキーマが追加。 今まで投入されていたデータに追加されたカラムはnullが入る。
スキーマが追加。 今まで投入されていたデータに追加されたカラムはnullが入る。
新しいスキーマに、旧データを投入
(スキーマは変更したが、投入するデータは以前と同じ)
# bq load --source_format=NEWLINE_DELIMITED_JSON logs.sample nested01.data.json
Upload complete.
Waiting on bqjob_r73583e1d3c68485e_000001672bece222_1 ... (0s) Current status: DONE
エラーにはならず、単純に新しいスキーマにはnullが入る 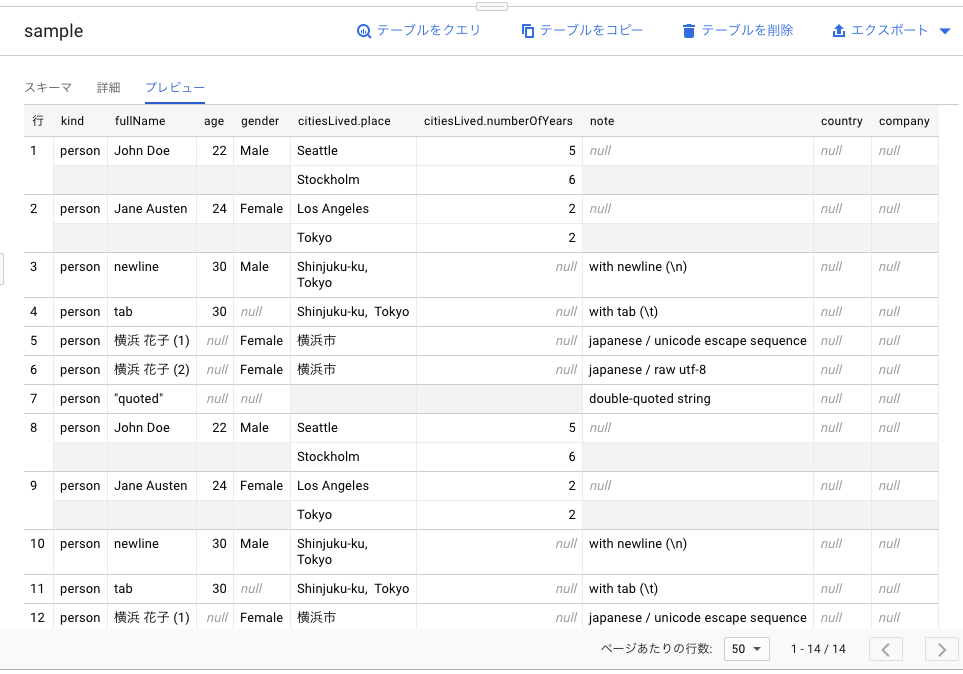
新スキーマに沿ったデータを投入
{"gender": "Male", "fullName": "John Doe", "age": 22, "citiesLived": [{"numberOfYears": 5, "place": "Seattle"}, {"numberOfYears": 6, "place": "Stockholm"}], "kind": "person", "country": "Japan", "company": "A company"}
{"gender": "Female", "fullName": "Jane Austen", "age": 24, "citiesLived": [{"numberOfYears": 2, "place": "Los Angeles"}, {"numberOfYears": 2, "place": "Tokyo"}], "kind": "person", "country": "USA", "company": "B company"}
{"note": "with newline (\\n)", "kind": "person", "gender": "Male", "age": 30, "fullName": "newline", "citiesLived": [{"place": "Shinjuku-ku,\nTokyo"}], "country": "Japan", "company": "A company"}
{"note": "with tab (\\t)", "age": 30, "fullName": "tab", "citiesLived": [{"place": "Shinjuku-ku,\tTokyo"}], "kind": "person", "country": "USA", "company": "B company"}
{"note": "japanese / unicode escape sequence", "gender": "Female", "citiesLived": [{"place": "\u6a2a\u6d5c\u5e02"}], "fullName": "\u6a2a\u6d5c \u82b1\u5b50 (1)", "kind": "person", "country": "Japan", "company": "A company"}
{"note": "double-quoted string", "fullName": "\"quoted\"", "kind": "person"}
# bq load --source_format=NEWLINE_DELIMITED_JSON logs.sample nested01.data.json
Upload complete.
Waiting on bqjob_r34be71bb151950ee_000001672bf33c1d_1 ... (0s) Current status: DONE
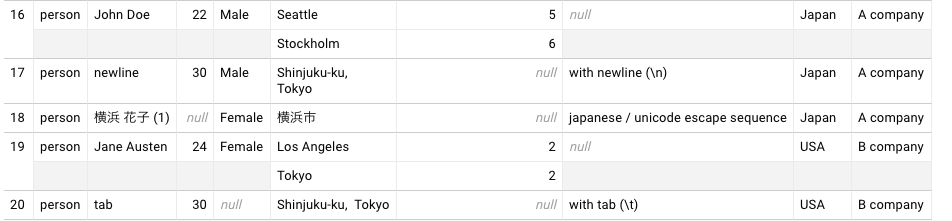 投入された
投入された
テーブル作成
jsonファイルを作成する
[
{
"name": "register_day",
"type": "STRING"
},
{
"name": "rtime",
"type": "STRING"
},
{
"name": "tid",
"type": "INTEGER"
},
{
"name": "sid",
"type": "INTEGER"
},
{
"name": "flag",
"type": "INTEGER"
},
{
"name": "id",
"type": "INTEGER"
},
{
"name": "lesson_date",
"type": "TIMESTAMP"
}
]
jsonファイルを用意して、bqコマンドで作成する
bq mk --table --expiration 3600 --description "This is my table" --label organization:development logs.mytable testTable.json
Table ‘***:logs.mytable’ successfully created. と表示されたら成功。 ブラウザで確認すると、問題なく作成されている。 
スキーマ変更
[
{
"name": "register_day",
"type": "STRING"
},
{
"name": "rtime",
"type": "STRING"
},
{
"name": "tid",
"type": "INTEGER"
},
{
"name": "sid",
"type": "INTEGER"
},
{
"name": "flag",
"type": "INTEGER"
},
{
"name": "id",
"type": "INTEGER"
},
{
"name": "lesson_date",
"type": "TIMESTAMP"
},
{
"name": "lesson_date2",
"type": "TIMESTAMP"
}
]
lesson_date2を追加し、bq update コマンドを実施
bq update logs.mytable testTable.json
Table ‘****:logs.mytable’ successfully updated.
となれば成功 無事カラムが追加された 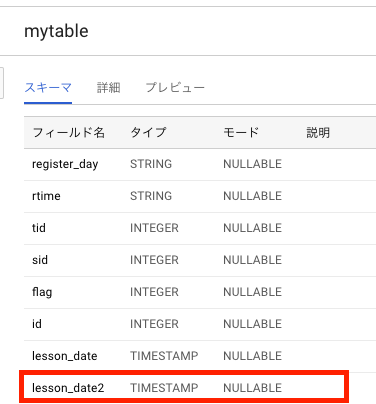
テーブル定義をdumpする
bq --format=prettyjson show --schema tsukadaproject:logs.logsPartition > bbbb
[
{
"mode": "NULLABLE",
"name": "register_day",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "rtime",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "lesson_date",
"type": "TIMESTAMP"
}
]
当然このformatを読み込ませることができる
bq mk --table --expiration 3600 --description "This is my table" --label organization:development logs.bbbb bbbb
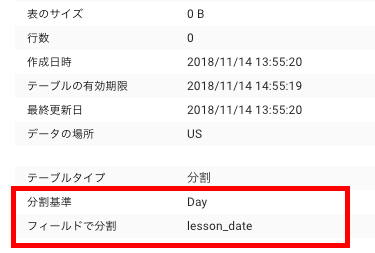
パーティションテーブルを作成する
JSONはスキーマ情報のみ。パーティションテーブルの指定はbqコマンドのオプションで行う。
[
{
"mode": "NULLABLE",
"name": "register_day",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "rtime",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "lesson_date",
"type": "TIMESTAMP"
}
]
パーテョションテーブル作成
bq mk --table --expiration 3600 --description "This is my table" --time_partitioning_field=lesson_date --time_partitioning_type=DAY --label organization:development logs.cccc cccc
Table ‘****:logs.cccc’ successfully created.
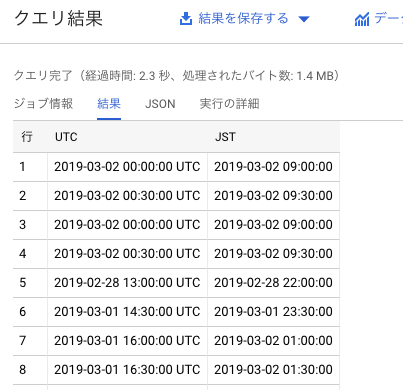
参考情報
ストーリー仕立てで分かりやすくまとまっているのでおすすめ。







 “` ./script.sh tsukada-test start “`
“` ./script.sh tsukada-test start “`  本来ならCloudFunctionで実装したかったが、大いにはまってしまったので、急遽この方法で対応した。
本来ならCloudFunctionで実装したかったが、大いにはまってしまったので、急遽この方法で対応した。