はじめに
redashは去年の年末頃Version 4が出て、夏にVersion 5、そしてVersion 6が近日リリースというスピードで、どんどんメジャーバージョンアップを繰り返し、機能が拡充されています。
レアジョブではDocker版 redash Version 1.03で初めてredashを導入し、何度もVersion UPを繰り返し現在は最新版(5.02)を使っています。
そこで得た知見についてはメモを書いていましたが、( https://tsukada.sumito.jp/category/tech/redash/ ) あくまでもメモベースなので、これを機にちゃんとブログとしてまとめたいとおもいます。
弊社での利用者
アルバイトから役員まで、様々なロールを持ってる人が使ってます。
Botも動いており、一部APIを使い、Chatに通知する仕組みも取り入れています。
SQLを書ける人を増やしたい
最初は非エンジニアの方は書けない人が大半でした。
社内勉強会を定期的に開き、誰でもSQLを書ける土台を作りました。
社内勉強会の成功は「自分ゴト化」がキモ。非エンジニアにSQLを教えた話

https://appeal.rarejob.co.jp/2016/11/11/2174/
それでもすぐにSQLが書けるようにはならないので、足りない部分はchatで専用の窓口を開き、SQLやredashについて気軽に質問できる土台を作りました。
redashの使い方についてはkakakakakkuさんのhandson資料を使わせてもらい、社内でredash使える人を増やしました。
https://github.com/kakakakakku/redash-hands-on
APIを使いたい
残念ながらAPIについてのドキュメントはあまりありません。
ソースを見るのが一番早かったりします。
https://github.com/getredash/redash/blob/master/redash/handlers/api.py
運用編
redashのコンテナの役割を知りたい
以前Qiitaにまとめた記事にredash_serverコンテナがどのような振る舞いをしているのかまとめた。
https://qiita.com/S-T/items/bee0ae9c8c0acbd940cc
redashのバックアップを取りたい
基本的にredashのデータはredashのPostgresに入ります。redisはキャッシュ情報が入るのでこちらはバックアップの対象外で問題ありません。(自分はクエリが詰まったらredisの中身を全部空にしたりします)
我々はDockerで動かしているので、host側から以下のcronを仕込んでます。
0 6 * * * /bin/docker exec redash_postgres_1 pg_dump -U postgres postgres | /bin/gzip > /tmp/redash_backup.gz
このバックアップで取得できたファイルを、定期的に別サーバやS3に格納しています。
redashのクエリのバックアップを取りたい
redashに登録したクエリをバックアップし、世代管理したい事が多々あります。
@ariarijp さんが作成した redashman (https://github.com/ariarijp/redashman) というツールが非常に便利です。
どこでも動くように、という事を念頭に開発されたようでgo言語で作られています。
定期的に実行し、gitで保存するようにしています。
redashのメジャーVersion UPをしたい
オフィシャルの手順はこちらです。
https://redash.io/help/open-source/admin-guide/how-to-upgrade
作業前にPostgresのバックアップを取得することを強くお勧めします。
私がVersion UPした際の手順は以下の通りです。
メジャーバージョンアップを行う場合、DBのスキーマ変更を伴う場合が多いです。
https://tsukada.sumito.jp/2018/08/08/docker-redash-v5-update/
redashのマイナーバージョンアップをしたい
docker-composeでdockerのイメージを切り替えるだけで動く事が多い。
作業前にPostgresのバックアップを取得することを強くお勧めします。
https://hub.docker.com/r/redash/redash/tags/
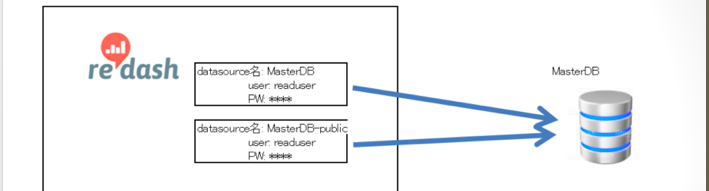
誰にどのデータを見せるかの制御したい
様々なロールを持ってる人がredashを使っています。
単純にKPIを追う人、センシティブな数値を扱う人と様々です。
残念ながら現段階ではredashではオフィシャルに「見せる・見せない」を制御する機能はありません。
データソースをもう一つつくり、そちらで制御するようにしました。
https://qiita.com/S-T/items/c0e4bf3929771a30b720
クエリが詰まる原因を知りたい
クエリを実行したのに、結果が返ってこない。ということはよくあります。
いわゆる「クエリが詰まる」という状況です。
なぜ、どのような理由で詰まるのか。これについては @ariarijp さんのスライドが非常にわかりやすくまとまってます。
詰まる箇所、つまり、全部。というわけです。
クエリが詰まった。対処したい
根本対応ではないのですが、前途したように、redisの中身をdeleteしてます。
https://tsukada.sumito.jp/2018/08/25/redash-v5%E3%81%A7in-progress%E7%8A%B6%E6%85%8B%E3%81%AE%E3%82%BE%E3%83%B3%E3%83%93%E3%83%97%E3%83%AD%E3%82%BB%E3%82%B9%E3%82%92kill%E3%81%99%E3%82%8B/
このような状況に陥った場合は、host側のswapも相当使用している可能性があるのでOSの再起動も合わせて行なってます。
CLIで操作したい
「redashのユーザーを作成してください」というのはredashを運用していてとても多いオペレーションです。
GUIでもよいのですが、エンジニアにとってはCLIでやりたいこともあります。
- ユーザー確認
docker exec -it redash_server_1 ./manage.py users list
- ユーザー作成
docker exec -it redash_server_1 ./manage.py users create tsukada@sumito.jp tsukada
- ユーザーパスワード変更
docker exec -it redash_server_1 ./manage.py users password tsukada@sumito.jp password
- ユーザー削除
docker exec -it redash_server_1 ./manage.py users delete tsukada@sumito.jp
ただし、ユーザーに行動履歴があると、削除できません。その場合は履歴情報を削除してからCLIを実施する必要がありました。
この点はVersion 5から改善され、GUIでユーザーをdisable化できるようになりました。
そのため、現在弊社ではユーザーを削除するというオペレーションは行なっておりません。
誰がどのクエリを実行したのか知りたい
実は全てのクエリはredashのpostgresに保存されています。
redashにログインし、 /admin に接続すると、管理者用のページが表示されます。
但し、このページはadminのみアクセスが可能なページです。
複数のデータソースを結合したい
データソースAとデータソースBを結合することができます。joinのようなものです。
Gunosyさんのブログに詳しい使い方が書いてあります。
簡単にいうと、以下のようなクエリを書き、datasourceにQueryResultsを選択すると結合できます。
select *
from query_59 a
join query_96 b
where a.member_id = b.member_id;
Dynamo DBをSQLで操作したい
DynamoDBはDQLというSQLっぽいんだけど、SQLじゃないオリジナルの言語を使います。これが細かいところに手が届かなかったり、これが馴染みの無い人には辛い。
QueryResultを経由させてSQLで操作できるようにします。
https://tsukada.sumito.jp/2018/10/05/redash-query-result-dql/
BigQueryを操作したい
BigQueryはScan対象のカラムによって課金される。redashは実際に何行読み込み、容量は何kbyteだったのか表示してくれます。親切。
redashのUserをgitで管理したい
前途したuser listをCLIで表示させ、gitと連携しユーザの棚卸しを行なっている。
ただし、Version 5でUserのenable/disable機能が組み込まれたが、CLIで確認することができなかった。一部昨日追記したところ、無事取り込んで戴けました。
https://github.com/getredash/redash/pull/2951/files
メリットは以下の通りです。
redashにコントリビュートしたい
CLIは穴場です。必要なものがまだ実装されておらず、且つ比較的簡単に実装できたりします。
とはいえ、どのようにはじめたらいいかわからない、という方はぜひredashのdeveloper meeetupにお越しください。
もくもくを経て、一人一人発表、フィードバックを得れる会です。その為参加人数も絞ってます。プルリク送ってコントリビュートしたい方、是非。
会場は前回に引き続き、弊社レアジョブです。
https://redash-meetup.connpass.com/event/110549/