

はじめに
mysqlはオフィシャルのdocker imageを提供しているが、実はこれがいろいろ便利だったりするので紹介。
https://hub.docker.com/_/mysql/
Initializing a fresh instance
When a container is started for the first time, a new database with the specified name will be created and initialized with the provided configuration variables. Furthermore, it will execute files with extensions .sh, .sql and .sql.gz that are found in /docker-entrypoint-initdb.d. Files will be executed in alphabetical order. You can easily populate your mysql services by mounting a SQL dump into that directory and provide custom images with contributed data. SQL files will be imported by default to the database specified by the MYSQL_DATABASE variable.
/docker-entrypoint-initdb.dへ.sh, .sql and .sql.gzファイルを置けば、アルファベット順に読まれる。SQLファイルはimportされる。
何も考えず置けばよいらしいのだ。Dockerfileにいろいろ書かないで済むようなのである。
やってみた
昔MySQLはサンプルデータを公開していると書いたし、せっかくなので、そのデータをつかう。 https://qiita.com/S-T/items/923cf689ee5f44525457
http://downloads.mysql.com/docs/world.sql.gz
をダウンロードすることにする
Dockerfileを記載
MySQL 5.7のオリジナルイメージを持ってきて、
先ほどダウンロードしたsql.gzファイルを/docker-entrypoint-initdb.dにコピー。
FROM mysql:5.7 COPY world.sql.gz /docker-entrypoint-initdb.d/world.sql.gz
これだけ。
buildする
# docker build ./ -t mysql-sampledata Sending build context to Docker daemon 94.72kB Step 1/2 : FROM mysql:5.7 ---> 141eda20897f Step 2/2 : COPY world.sql.gz /docker-entrypoint-initdb.d/world.sql.gz ---> 9776c5f28986 Removing intermediate container f8fa93b7eb40 Successfully built 9776c5f28986 Successfully tagged mysql-sampledata:latest
無事docker imageが出来上がった
# docker images REPOSITORY TAG IMAGE ID CREATED SIZE mysql-sampledata latest 9776c5f28986 15 seconds ago 372MB mysql 5.7 141eda20897f 9 days ago 372MB
このmysql-sampledataを起動させる。
docker run -e MYSQL_ALLOW_EMPTY_PASSWORD=yes -d mysql-sampledata
MYSQL_ALLOW_EMPTY_PASSWORDオプションでパスワード無しでログインできるようになる。
https://hub.docker.com/_/mysql/
MYSQL_ALLOW_EMPTY_PASSWORD
This is an optional variable. Set to yes to allow the container to be started with a blank password for the root user. NOTE: Setting this variable to yes is not recommended unless you really know what you are doing, since this will leave your MySQL instance completely unprotected, allowing anyone to gain complete superuser access.
パスワードを付与したい場合は以下のオプションを利用する
“` -e MYSQL_ROOT_PASSWORD=mysql “`
ログインしてみる
docker exec -it $(docker container ls | grep 'mysql-sampledata' | awk '{print $1}') /bin/sh
パスワードなしでmysqlの中に入れる
# mysql -uroot -p Enter password:
show databases;を行うと、先ほどimportしたworldというデータベースが見える
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | world | +--------------------+ 5 rows in set (0.00 sec) mysql>
もちろん中身もある
mysql> use world; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A mysql> show tables; +-----------------+ | Tables_in_world | +-----------------+ | city | | country | | countrylanguage | +-----------------+ 3 rows in set (0.00 sec) mysql>
mysqldumpの結果を入れることもできるし、いろいろ使えそうだ。
外部から接続する場合
ポートを付与する。
# passwordあり docker run --name mysql -e MYSQL_ROOT_PASSWORD=mysql -d -p 3306:3306 mysql-sampledata # passwordなし docker run --name mysql -e MYSQL_ALLOW_EMPTY_PASSWORD=yes -d -p 3306:3306 mysql-sampledata
mysql -uroot -h127.0.0.1 -pmysql






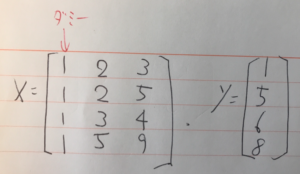
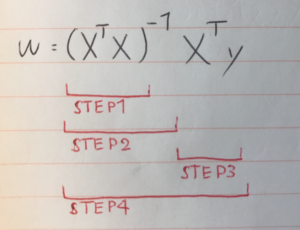
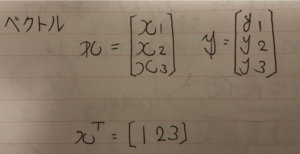
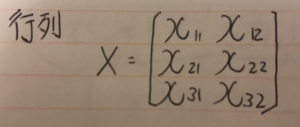
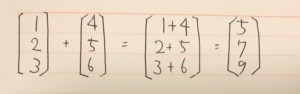
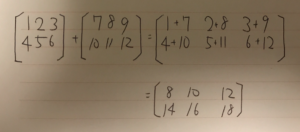
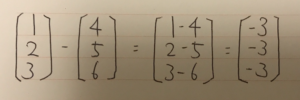
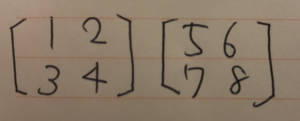
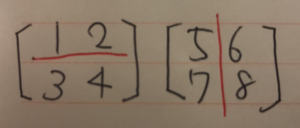
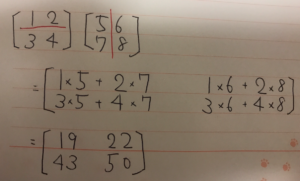
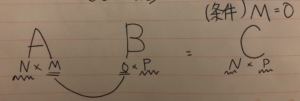
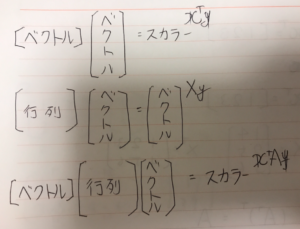
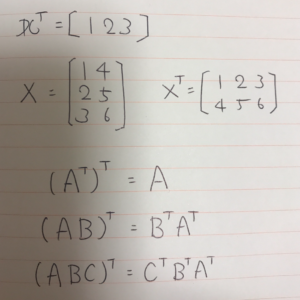

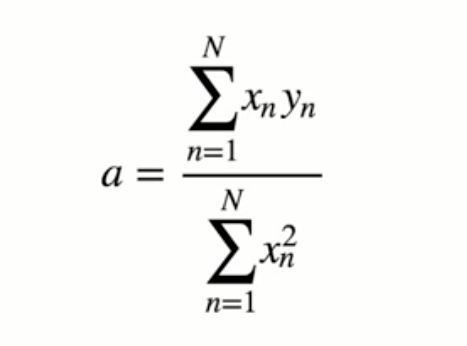 難しそうなインパクトが強すぎて中身がまったく頭に入ってこない。 これをnumpyで実装する。
難しそうなインパクトが強すぎて中身がまったく頭に入ってこない。 これをnumpyで実装する。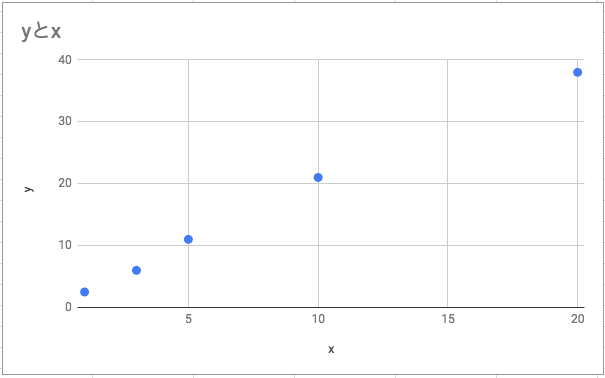 データの中心化を行う。値から、平均分を引く
データの中心化を行う。値から、平均分を引く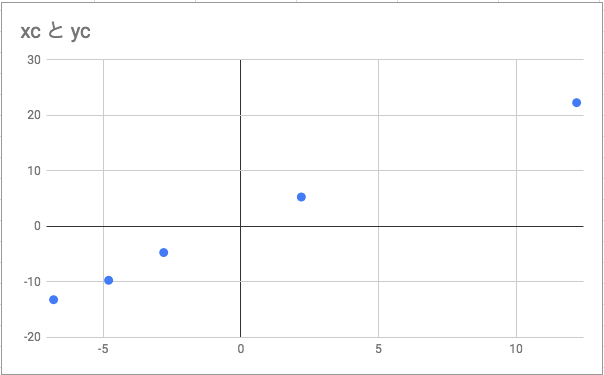
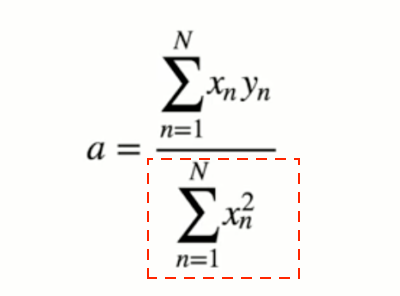 numpyで計算する際は、このようになる
numpyで計算する際は、このようになる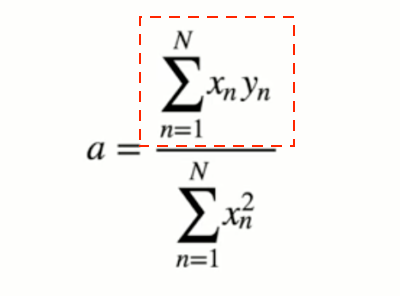 次に分子
次に分子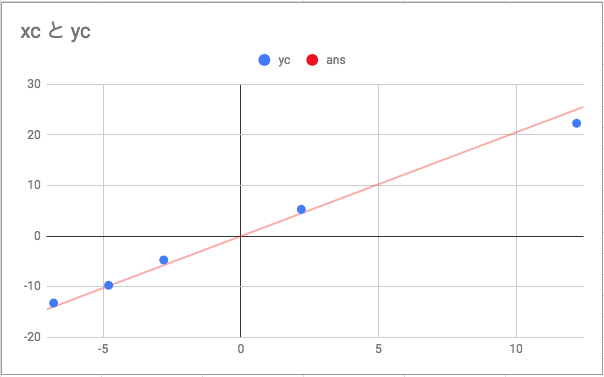 悪くなさそう。 実は実際はscikit-learnを使うともっと早いようだ。
悪くなさそう。 実は実際はscikit-learnを使うともっと早いようだ。  “` ./script.sh tsukada-test start “`
“` ./script.sh tsukada-test start “`  本来ならCloudFunctionで実装したかったが、大いにはまってしまったので、急遽この方法で対応した。
本来ならCloudFunctionで実装したかったが、大いにはまってしまったので、急遽この方法で対応した。