
転送コストを部署毎に分配する際の対応
AWS Direct Connect経由のデータ転送のコストを各部門にどのように分配すべきか
- 仮想インターフェースを構成
- 仮想インターフェースの所有者を部門のAWSアカウント番号に設定する

AWS Direct Connect経由のデータ転送のコストを各部門にどのように分配すべきか
EBS backedインスタンスは停止および再起動が可能
その月にIOPSおよびストレージを実際に使用したかどうかに関係なく課金される
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/EBSVolumeTypes.html
スナップショット作成時はデータ整合性を保つため静⽌点を設ける必要がある。
EBSは増加バックアップでS3に保存する事が可能。
基本(Basic)は5分間のデータを無料で自動に取得可能
プライベートホストゾーンに関連付けさせる必要がある。
| インスタンスファミリー | 特徴 |
|---|---|
| M5 | 汎用 |
| T2 | 汎用 |
| C5 | コンピューティング最適化 |
| H1 | ストレージ最適化 |
| D2 | ストレージ最適化 |
| R4 | メモリ最適化 |
| X1 | メモリ最適化 |
| F1 | FPGA |
| G3 | GPC |
ELBのクロスゾーン負荷分散を利用する事で、ロードバランサに登録されている複数のAZのAmazon EC2インスタンス間で、受信トラフィックを均等に分散させる事が可能。
作成したEC2インスタンスを作成し、インターネットに接続できない場合は、NATゲートウェイサブネットに、インターネットゲートウェイへのルートがない可能性があるので、確認する。
5秒ごと
5分
1分
単一のVPCにパブリックサブネットが1つデフォルトで設定される
VPCを設置しないでEC2インスタンスを立ち上げる場合、サブネットの設定が必須になる
グローバルIPを持つAWSサービスに対して、VPCの内部から直接接続するための出口。
Gateway型はサブネットに特殊なルーティングを設定し、VPC内部から直接外のサービスと通信する
VPC peeringは一部のリージョン間に限られている。
サブネットにエンドポイント用のプライベートIPを設定して使用する
エンドポイントポリシーによりアクセス制御を実施
accepted/rejectedされたトラフィックを保持する
10分間で収集・プロセッシング・保存する
VPC内の全てのIPアドレスを利用している場合は、VPCのCIDRブロックを変更して、新しいサブネットに十分な空きスペースを作成する事で枯渇時対処することも可能。
セキュリティを高める際に利用する
具体的には、アプリケーションが動いているインスタンスは他のAWS顧客とハードウェアを共有してはいけない場合、以下の構成を検討する事ができる
Amazon RDS MySQL DBインスタンスで現在、利用可能な最大のインスタンスタイプで実行されているとする。
DBインスタンスはCPUおよびネットワーク帯域幅に近いキャパシティで動作。
今後、トラフィックが増加することを予想される。より多くのトラフィックを捌くアプローチ
プライマリDBインスタンスに障害が発生した場合、RDSマルチアベイラビリティゾーンのデプロイは、
標準名レコード(CNAME)がプライマリからスタンバイに変更される。
セッション情報をRDSではなく、ElasticCacheを利用する際の挙動
追加ストレージを割り当てる事が可能。割り当て中にパフォーマンスが低下する期間を計画する。

dynamodbへまとめてデータを入れたい時がある。バルクインポートの手順を紹介
{
"tsukada-tw": [
{
"PutRequest": {
"Item": {
"ID": {"N":"1"},
"Tip": {"S":"【保存版】プレゼンで使えるグラフや図を表現する英語フレーズ集 https://www.rarejob.com/englishlab/column/20190426/"
}
}
}
},
{
"PutRequest": {
"Item": {
"ID": {"N":"2"},
"Tip": {"S":"海外でも母の日は祝うもの? Mother’s Dayの時期や英語のお祝いメッセージを紹介! https://www.rarejob.com/englishlab/column/20190425/"
}
}
}
},
{
"PutRequest": {
"Item": {
"ID": {"N":"3"},
"Tip": {"S":"英文メールの結びにはなんて書けばいい?ビジネスからカジュアルまで「よろしく」や「敬具」に代わる結びの英語表現まとめ https://www.rarejob.com/englishlab/column/20190424/"
}
}
}
}
]
}
aws dynamodb batch-write-item --request-items file://bulk.json


資格こそ取っていないが、AWSは常に触っている。試験を受ける受けないは別にして、知識をあるレベルまで引き上げる上で、試験用の本から多くのことを学ぶことができる。
今回は「徹底攻略AWS認定ソリューションアーキテクトアソシエイト教科書」を通じて得られた知識についてまとめた。
| mode | 解説 |
|---|---|
| 迅速 | オンデマンドと呼ばれる。 成功する保証がない |
| 標準 | 3~5時間でアーカイブから取り出しが可能 |
共有ストレージ。ユーザー側でスナップショット取得不可
エフェメラルディスクとも呼ばれる。EC2停止時にはデータは消失。再起動では消失しない
データは3箇所のAZに格納される
1つのAZにつき2箇所のディスクに書き込まれる => 合計6箇所に保存される
結果整合性モデルが一部採用されている
| メソッド | 種別 | 特徴 |
|---|---|---|
| PUT | 新規追加 | 書き込み後の、読み込み整合性 |
| PUT | 更新 | 結果整合性 |
| DELETE | 削除 | 結果整合性 |
メッセージの送信、受信のアクセスポイント
TOPICを作成し、購読者が購読することで通知の送受信が可能になる
TOPICから発信されるメッセージの購読者を設定
の利用が可能
作成したTOPICに対してアプリケーションからメッセージを送信。
送信されたメッセージはSQSから購読者(サブスクライバ)へ配信される
定義ファイルをテンプレートと呼ぶ
テンプレートから呼び出されるサービスの集合を、スタックと呼ばれる
システムが正常に継続して動作し続ける能力
指標はパーセンテージ。一般的に稼働率と呼ばれる。
スケーリングプラン設定値が閾値超え
↓
EC2インスタンスを増加(Auto Scalingグループの設定値に従う)
EC2インスタンス数が最も多いAZからランダムに選ばれる
もしインスタンス数が同じ場合は、最も古いEC2インスタンスがあるAZが選ばれる
それも同じ場合は、次に課金が発生する時間が最も短いEC2インスタンスが選ばれる
それも同じ場合は、この中からランダムに選ばれる
Auto Scalingが連続で実施されないようにする待ち時間
アプリケーションのバグや、オペレーションミスの場合、RDSの自動再起動を行う。
フェールオーバでの復旧が不可能な場合、バックアップからのリストアをする必要がある。
標準のスナップショット機能を用いる
EBS もしくは AMIで取得したバックアップを用いて、リストアを行う
単一のAZ内のEC2インスタンスを論理的にグルーピング
複数のコンピューティングリソースを1つとして機能させる。
クラスターコンピューティングに最適
EC2 ⇔ EBS間
EC2 ⇔ その他が同一のネットワークになる
EC2 ⇔ EBS間が専用のネットワークになる
DynamoDBのインメモリキャッシュ。
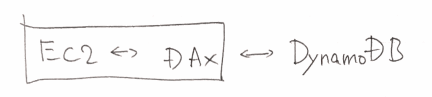
のように使う
Google/FacebookなどのOpenID Connectをサポート
どちらもユーザがAWSで鍵を管理・保管するサービス
クライアントサイド(CSE)
サーバサイド暗号化(SSE)
AWSのサービスでは、Deployができるサービス、Provisioningができるサービス、その両方が可能なサービスが存在する。まとめると以下の通り。
| Service | Deploy | Provisioning |
|---|---|---|
| OpsWork | ○ | ○ |
| Elastic Beanstalk | ○ | ○ |
| Code Deploy | ○ | × |
| Cloud Formation | × | ○ |
Consolidated Billing(一括請求)で統合可能
メンバーのアカウント(Linked Account)の請求を、
マスターのアカウント(Payer Account)に統合できる