tl;dr;
ER図などを自動生成してくれる SchemaSpy というツールがある。
このツールは接続先のDBを指定する事でそのDBサーバのスキーマ情報を読み取って解析してくれる作りだ。
しかし、DBに接続させたくない場合は多い。手元にcreate table文などを盛り込んだDDL文の塊を用意する事で対応できるようにした。
対処した事
と言っても SchemaSpy 自体をいじったわけではなく、SQLファイルを手元に用意して、DBのコンテナに読み込ませ、そのコンテナに対して SchemaSpy を叩かせるようにしただけ。
見えてきた未来
DBをダイレクトに繋ぎに行かずにすむ事で、ブランチごとにDB構成を管理することができるようになり、CIに組み込めばスキーマのレビューもしやすくなる。
考えなければならなかったところ
SchemaSpy が動く前にDBコンテナに適切にデータが作られてないといけない。
もしテーブルが作られていないと SchemaSpy が空振りしてしまい、期待している結果に至らないからだ。そのため、DBコンテナにテーブルが作られていることを確認してから SchemaSpy が動かす必要がある。
しかし、docker-compose では、それ自体で細かな起動順番を指定することができない。
docker 公式ドキュメントでも以下のような記載がある。
Compose はコンテナの準備が「整う」まで待ちません(つまり、特定のアプリケーションが利用可能になるまで待ちません)。単に起動するだけです。
http://docs.docker.jp/compose/startup-order.html
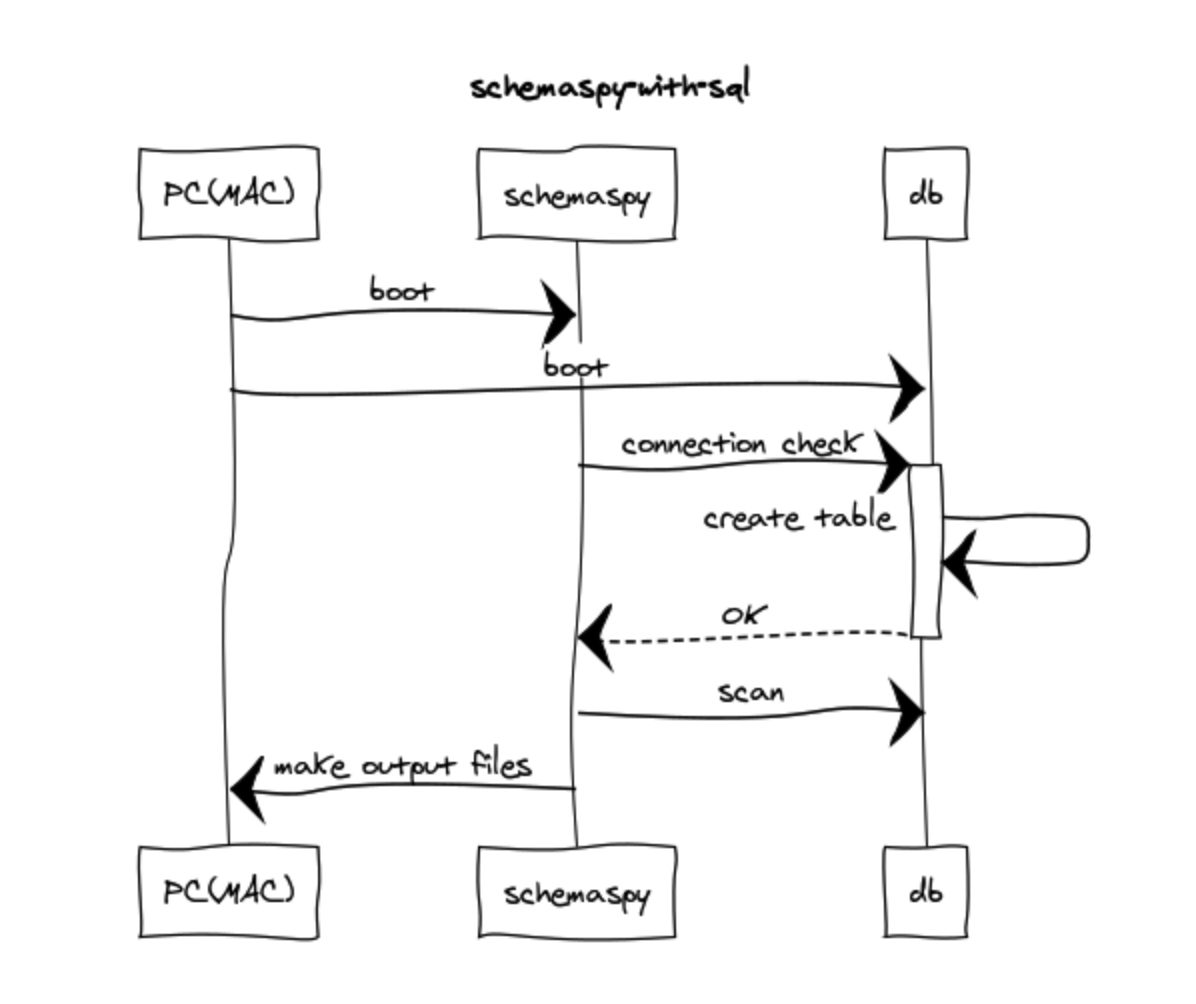
自分で制御するしかないようだ。起動したい順番をシーケンス図でかくとこのような感じ。
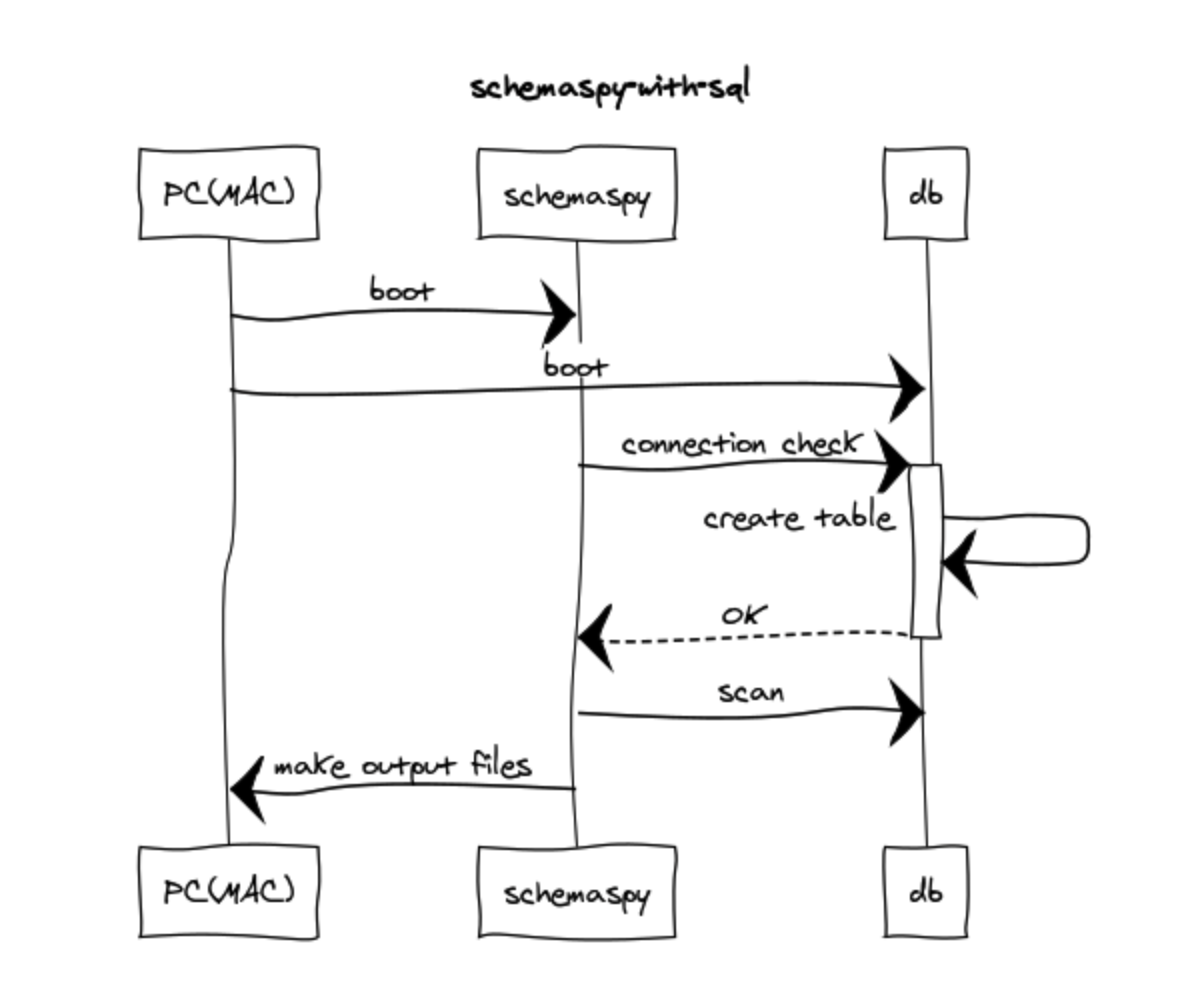
SchemaSpyコンテナ側での制御はシンプルにシェルで行っており、mysqlに繋がったら CREATE TABLE 含むDB側の準備は完了とみなし、SchemaSpy側の実際の処理をするようにした。
#!/bin/sh
set -e
echo $@
host=$1
shift
user=$1
shift
password=$1
shift
cmd="java -jar schemaspy.jar"
echo "Waiting for mysql"
until mysql -h"$host" -u"$user" -p"$password" &> /dev/null
do
>$2 echo -n "."
sleep 1
done
>&2 echo "MySQL is up - executing command"
exec $cmd
https://github.com/GitSumito/schemaspy-with-sql/blob/master/docker/schemaspy/bin/wait.sh
MySQLに繋がったらtableも作られていると解釈するのは危険ではないかと感じるかもしれない。
これは mysql のコンテナの設定を用いてもう少し説明したい。
version: '3'
services:
nginx:
image: nginx:latest
container_name: schemaspy_nginx
volumes:
- ./schemaspy:/var/www/html:ro
- ./docker/nginx/default.conf:/etc/nginx/conf.d/default.conf:ro
ports:
- "80:80"
environment:
- LANG=ja_JP.UTF-8
- TZ=Asia/Tokyo
schemaspy:
build: ./docker/schemaspy
image: treetips/schemaspy-mysql
container_name: schemaspy
volumes:
- ./schemaspy:/app/html:rw
- ./docker/schemaspy/config/schemaspy.properties:/app/schemaspy.properties:ro
environment:
- LANG=ja_JP.UTF-8
- TZ=Asia/Tokyo
working_dir: "/app"
depends_on:
- mysql
command: "sh -x /app/bin/wait.sh mysql docker docker employee java -jar schemaspy.jar"
# also modify db info docker/schemaspy/config/schemaspy.properties
mysql:
image: mysql:5.7
container_name: mysql_host
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: employee
MYSQL_USER: docker
MYSQL_PASSWORD: docker
TZ: 'Asia/Tokyo'
MYSQL_ALLOW_EMPTY_PASSWORD: "yes"
command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
volumes:
- ./docker/mysql/sql:/docker-entrypoint-initdb.d
ports:
- 3306:3306
https://github.com/GitSumito/schemaspy-with-sql/blob/master/docker-compose.yml
mysqlのvolumesでは
`./docker/mysql/sql` を`/docker-entrypoint-initdb.d`へマウントするよう設定している。
これはMySQLコンテナの仕様で、デフォルトでこのディレクトリの`.sh`ファイル、`.sql`ファイル、 `.sql.gz`ファイル があれば初期化段階で読み込み、MYSQL_DATABASEに指定したデータベースに作られる。
Initializing a fresh instance
When a container is started for the first time, a new database with the specified name will be created and initialized with the provided configuration variables. Furthermore, it will execute files with extensions .sh, .sql and .sql.gz that are found in /docker-entrypoint-initdb.d. Files will be executed in alphabetical order. You can easily populate your mysql services by mounting a SQL dump into that directory and provide custom images with contributed data. SQL files will be imported by default to the database specified by the MYSQL_DATABASE variable.
https://hub.docker.com/_/mysql
念のためdocker-compose をupしてログを確認してみると、`mysqld: ready for connections.`になる前に、実行されている。
mysql_host | 2020-01-19 23:12:16+09:00 [Note] [Entrypoint]: Creating database employee
mysql_host | 2020-01-19 23:12:16+09:00 [Note] [Entrypoint]: Creating user docker
mysql_host | 2020-01-19 23:12:16+09:00 [Note] [Entrypoint]: Giving user docker access to schema employee
mysql_host |
mysql_host | 2020-01-19 23:12:17+09:00 [Note] [Entrypoint]: /usr/local/bin/docker-entrypoint.sh: running /docker-entrypoint-initdb.d/001-create-tables.sql
(中略)
mysql_host | 2020-01-19T14:12:20.391989Z 0 [Note] mysqld: ready for connections.
mysql_host | Version: '5.7.29' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)
使ってみる
githubに置いておいたので適宜clone
git clone https://github.com/GitSumito/schemaspy-with-sql.git
make build
make up
その後、自分のPCにhttp接続するとSchemaSpyが作ったアウトプットを見ることができる。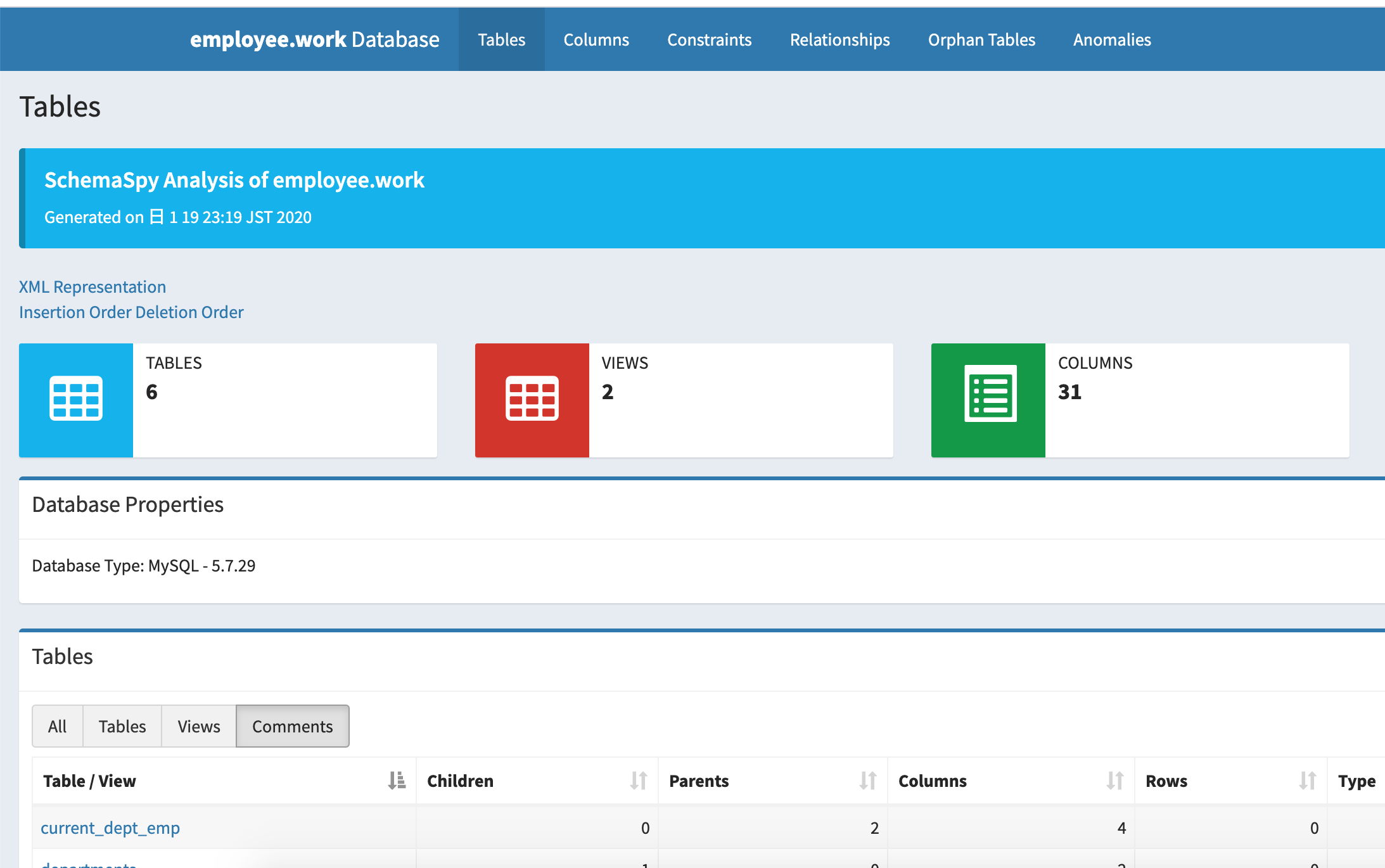
ER図はこのような感じ。非常に見やすい。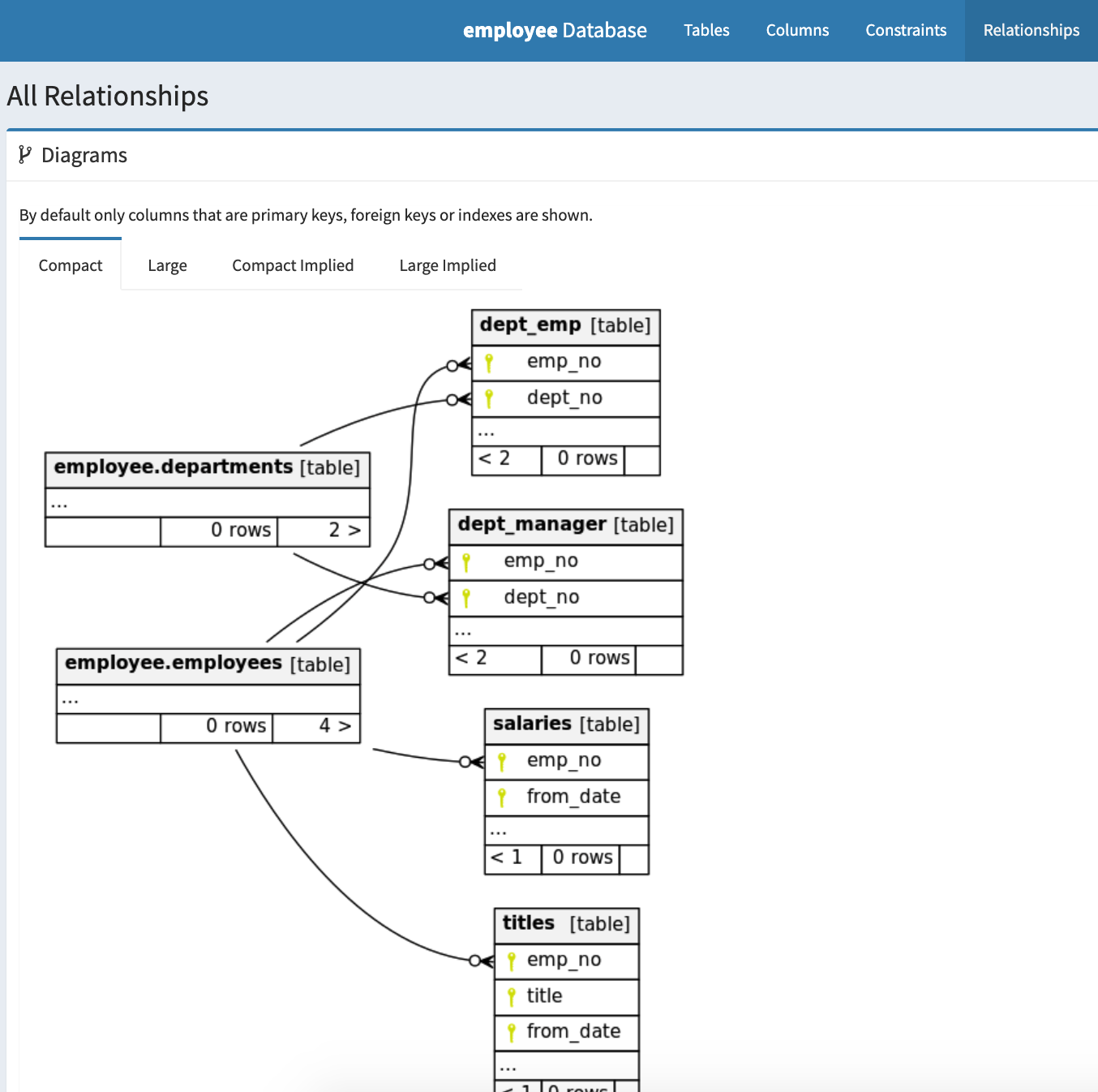
なお、今回はMySQLで公開されているemployeeテーブルから一部情報を使って描写した。
https://github.com/datacharmer/test_db/blob/master/employees.sql
手取り早く手元のDDLに置き換えたい場合は、
schemaspy-with-sql/blob/master/docker/mysql/sql/001-create-tables.sql
ファイルの中身を変更してdocker-composeを起動するだけでSchemaSpyを起動させることができるようにしてある。
最後に
Migraiton ファイルをそのまま読み込ませることができればもっと便利になると思うので、次回はその対処を行いたいと思う。