

概要
日本語の音声ファイルを文字起こししたい場合がある。真っ先に思い浮かんだのがAmazon transcribeだが、まだ日本語には対応していなかった。
調べたところ、Google Speech APIが日本語に対応していたのでこちらを使って文字起こしをしてみた。
サンプルの音声
iPhoneに付属しているボイスメモというアプリで録音した
https://itunes.apple.com/jp/app/%E3%83%9C%E3%82%A4%E3%82%B9%E3%83%A1%E3%83%A2/id1069512134?mt=8
今回はあくまでもサンプルなので、今日の日付を読み上げた。
加工
ボイスメモで録音したファイルはm4aファイルになる。
このフォーマットではGoogle Speech APIが対応していないのでwavファイルへ変換する。
Speech APIが対応しているファイルフォーマットは以下にまとまっている
https://cloud.google.com/speech-to-text/docs/encoding?hl=ja
macでは標準で付属しているafconvertというソフトを使う事で手軽に変換できる。
-d LEI16を指定する事で読み込める形になる。
afconvert -f WAVE -d LEI16 sample.m4a sample.wav
GCPの設定
コンソール画面左上の[ツールとサービス] > [APIとサービス] > [ライブラリ] を選択。
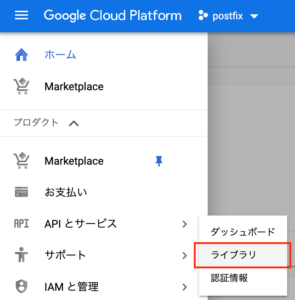
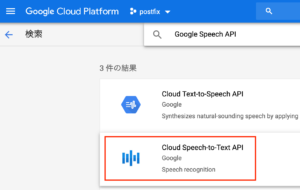
APIの一覧から[Speech API]を選択し、[有効にする]を押して を有効にする。
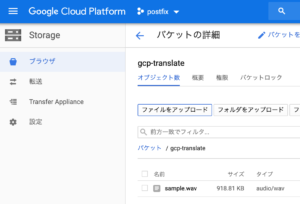
音声ファイルを格納
先ほど変換したwavファイルをCloud Storageに格納する。
文字起こし
Cloud Shellをアクティブにする
ジョブの登録
$ gcloud ml speech recognize-long-running gs://gcp-translate/sample.wav --language-code='ja-JP' --async
以下のようなレスポンスが来る
Check operation [441557619774374990] for status.
{
"name": "441557619774374990"
}
ステータス確認
$ gcloud ml speech operations describe 441557619774374990
以下のようなレスポンスが来る
{
"name": "441557619774374990",
"metadata": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeMetadata",
"progressPercent": 23,
"startTime": "2019-06-01T16:39:03.805780Z",
"lastUpdateTime": "2019-06-01T16:43:43.954310Z"
}
}
この画面で進捗率23%という事がわかる。
時間をおいて実施すると進捗率は変わる。
{
"name": "441557619774374990",
"metadata": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeMetadata",
"progressPercent": 86,
"startTime": "2019-06-01T16:39:03.805780Z",
"lastUpdateTime": "2019-06-01T16:52:40.778647Z"
}
}
進捗率が100%になったら、リダイレクトさせてtextに出力。
gcloud ml speech operations describe 441557619774374990 > test
ファイルを開き、中身を確認
cat test
{
"done": true,
"metadata": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeMetadata",
"lastUpdateTime": "2019-06-10T14:28:36.384592Z",
"progressPercent": 100,
"startTime": "2019-06-10T14:28:32.372249Z"
},
"name": "441557619774374990",
"response": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeResponse",
"results": [
{
"alternatives": [
{
"confidence": 0.9525875,
"transcript": "\u4eca\u65e5\u306f2019\u5e746\u670811\u65e5\u3067\u3059"
}
]
}
]
}
}
ファイルを開いた際、descriptionがエンコードされていなかったら適宜エンコードする必要がある。
最も手軽なのは、jqコマンドに渡す事で読めるフォーマットになる
$ cat test | jq -r '.'
{
"done": true,
"metadata": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeMetadata",
"lastUpdateTime": "2019-06-10T14:28:36.384592Z",
"progressPercent": 100,
"startTime": "2019-06-10T14:28:32.372249Z"
},
"name": "441557619774374990",
"response": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeResponse",
"results": [
{
"alternatives": [
{
"confidence": 0.9525875,
"transcript": "今日は2019年6月11日です"
}
]
}
]
}
}
今日は2019年6月11日です
という音声が無事取れた。
音声が綺麗に拾えていれば、これを使って文字起こしをする事ができそうだ。
コメント
“音声から日本語の文字起こしを行う” への1件のコメント
[…] 音声から日本語の文字起こしを行う […]