

はじめに
11/22 Amazon Transcribe が日本語に対応したという記事がリリースされました。
議事録とったりVoice memo作ったり何かと活用の場所がある機能。早速試してみました。
音声ファイルの準備
今回はiPhoneのボイスメモを利用することにします。アプリを消してしまった人もいると思うので念の為リンクを貼ります。
https://itunes.apple.com/jp/app/%E3%83%9C%E3%82%A4%E3%82%B9%E3%83%A1%E3%83%A2/id1069512134?mt=8
このアプリで録音した音声ファイルはm4aフォーマットになっているので、wavフォーマットに変換します。
macでは標準で付属しているafconvertというソフトを使う事で手軽に変換できます。
afconvert -f WAVE -d LEI16 sample.m4a sample.wav
音声ファイルのアップロード
解析対象の音源をs3に置く必要があり、作業用にバケットを作ります。
名前は今回以下のバケット名にしました。
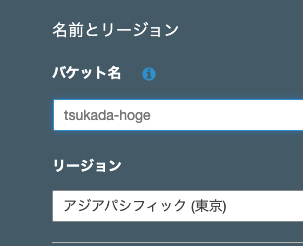
今回は全部デフォルトでポチポチと進ませバケットを作成しました。
作成されたバケットに変換後の音源をupload。
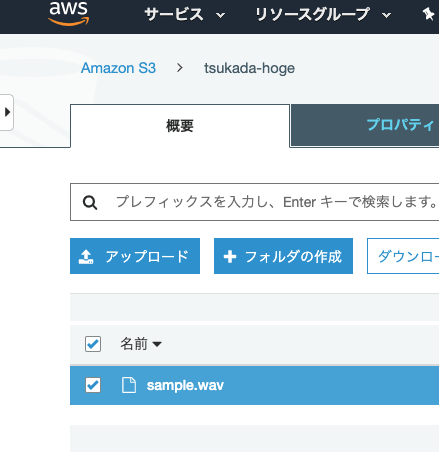
ここまでで準備は完了です。
Amazon Transcribeを開き、Create jobを押し、文字起こしのジョブを登録します。
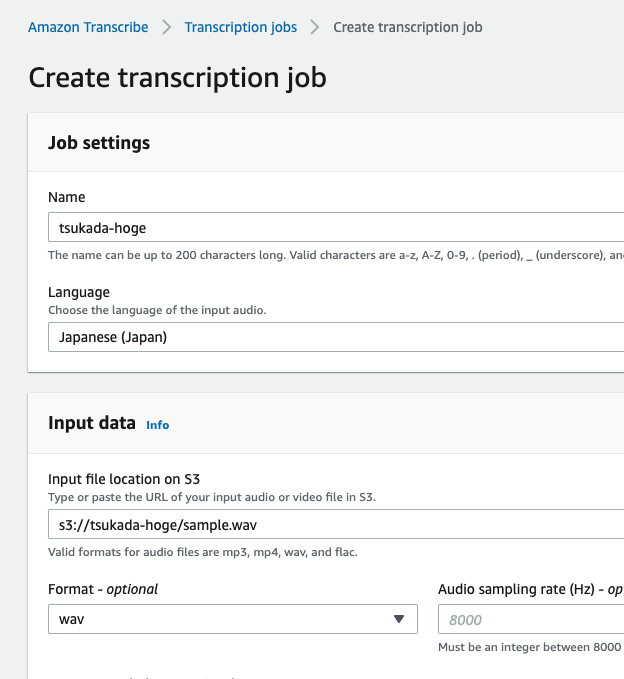
今回は以下の通り設定することにします。
Languageを今回追加されたJapaneseを指定することを忘れないでください。
inport dataは、S3に置いた音源のパスを。
Formatは変換後のフォーマットであるwavとしました。
Output dataでいくつか指定できますが、特に役立ちそうな機能はAlternative resultsです。
今回はこれを有効にして進めることにします。
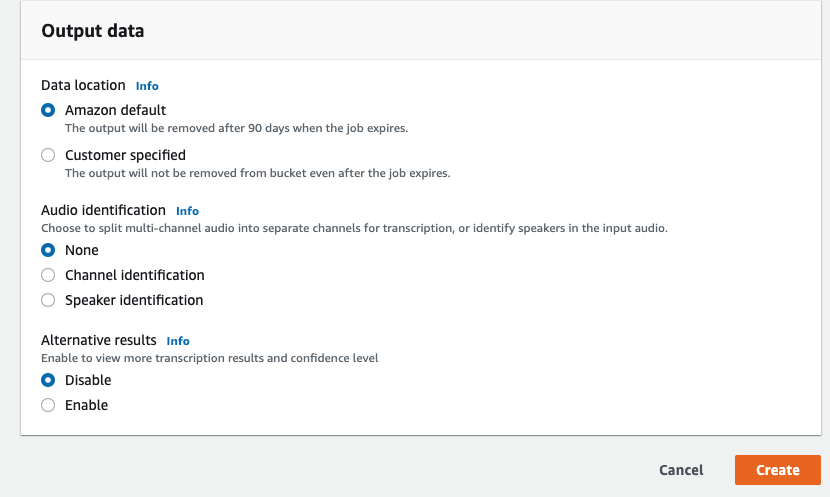
createを押します。
無事登録されたようです。
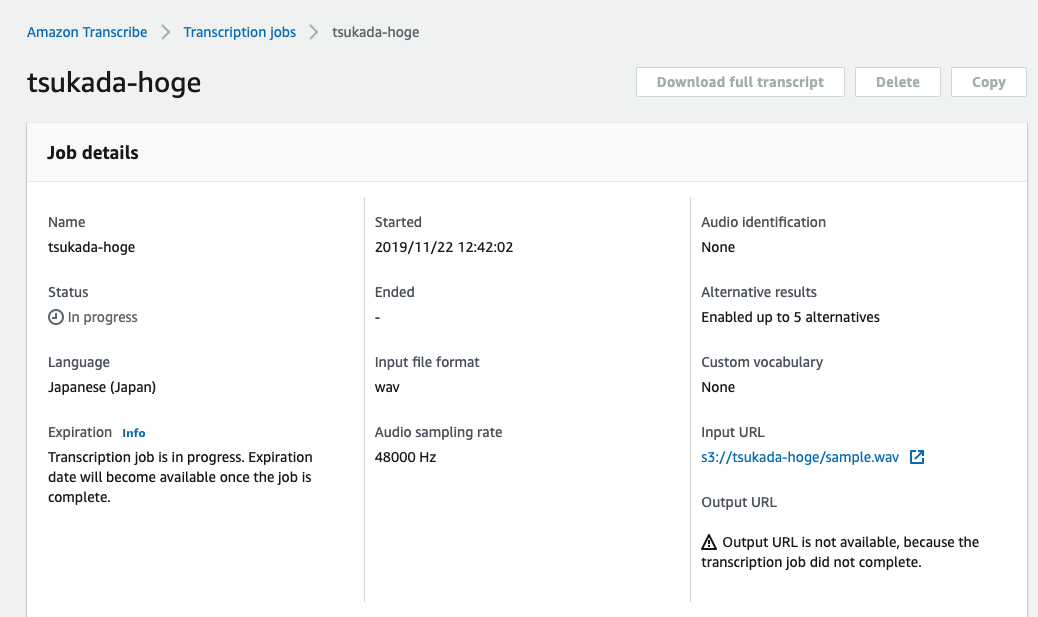
詳細情報を確認すると、StatusはIn progressになりました。暫くすると処理が始まりました。
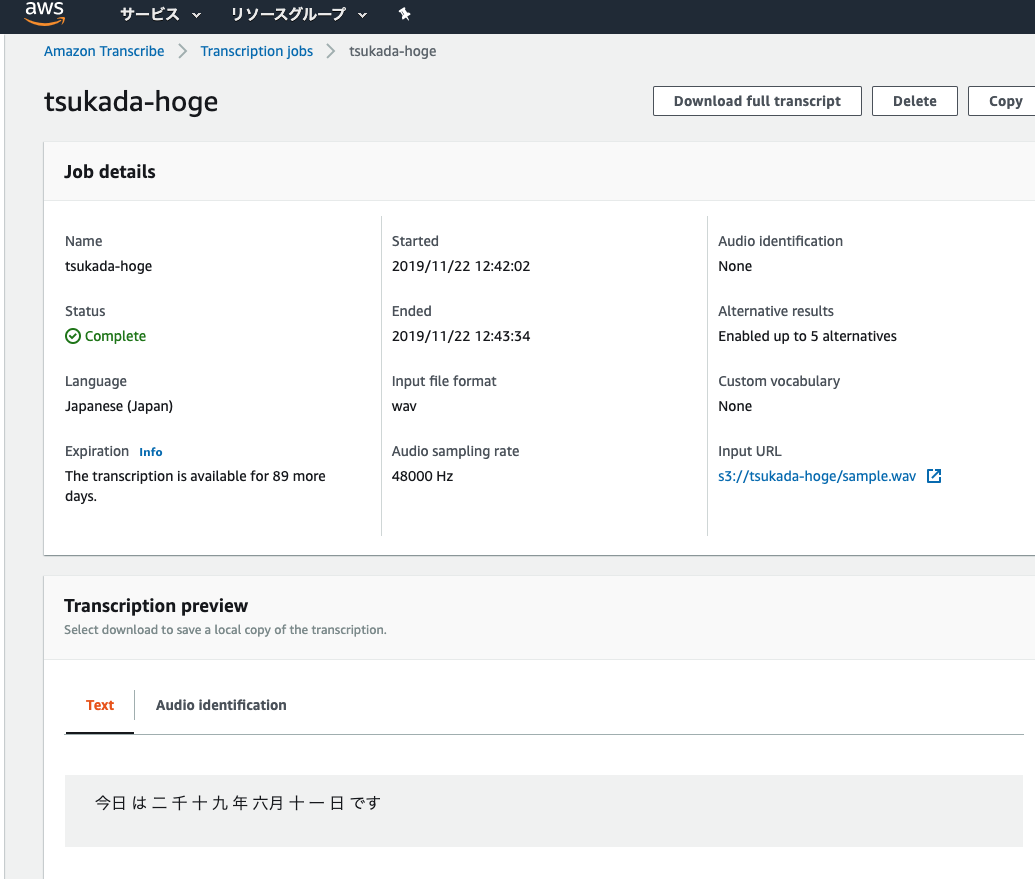
Transcriotion previewに、ちゃんと文字として表示されました。漢数字なのがちょっと読みづらいですね。
結果
jsonファイルで出力されます。
start_time, end_timeが表示され、実際どの部分が文字起こしされたのか非常にわかりやすいと感じました。
単語ごとにconfidenceが表示され、どれだけ的確かの指標にすることができるようです。
"results": {
"transcripts": [
{
"transcript": "今日 は 二 千 十 九 年 六月 十 一 日 です"
}
],
"items": [
{
"start_time": "0.84",
"end_time": "1.27",
"alternatives": [
{
"confidence": "0.9588",
"content": "今日"
}
],
"type": "pronunciation"
},
{
"start_time": "1.27",
"end_time": "1.4",
"alternatives": [
{
"confidence": "1.0",
"content": "は"
}
],
"type": "pronunciation"
},
まとめ
GoogleにもGoogle Speech APIという似たような機能があるがそちらは、今回のAWSはほとんどブラウザのみで完結できるので非エンジニアでも比較的簡単に利用することができそうです。
今回文字起こししたのはシンプルな言葉だったけど、長文を文字起こしした際、どれだけ読みやすいかなどは注視したいと思います。
参考情報
GCPで似たような機能があり、それは以前実施した。
https://tsukada.sumito.jp/2019/06/11/google-speech-api-japanese/