

はじめに
BigQueryは従量課金のモデルのため、スキャン量に応じて課金される。
いかにスキャン対象を減らすかが非常に重要になる。
通常のwhereで絞ったとしても、スキャンはされてしまうため課金を回避することができない。
そこで、partitioned-tables(分割テーブル)である。
partitioned-tables(分割テーブル)について
現時点で大きく2つ存在している
- 取り込み時間分割テーブル:
データを取り込んだ(読み込んだ)日付またはデータが着信した日付に基づいて分割されたテーブル。 - 分割テーブル:
TIMESTAMP列またはDATE列を基準にして分割されたテーブル
詳細はこちら
https://cloud.google.com/bigquery/docs/creating-partitioned-tables
通常のwhereのように使い、課金額を減らすのが目的であれ”取り込み時間分割テーブル”ではなく”分割テーブル”のが便利そうだ
やってみた
テーブル定義
まずはテーブル定義
[
{
"mode": "NULLABLE",
"name": "register_day",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "rtime",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "lesson_date",
"type": "TIMESTAMP"
}
]
テーブルを作成する
bq mk --table --expiration 3600 --description "This is my table" --time_partitioning_field=lesson_date --time_partitioning_type=DAY --label organization:development logs.cccc bbbb
lesson_dateが分割テーブルのパーティションとなる
読み込み
データはこんな感じ
{"register_day":"3320915", "rtime":"tsukada", "lesson_date": "2019-04-30 14:02:04"}
{"register_day":"3320915", "rtime":"tsukada", "lesson_date": "2019-05-30 14:02:04"}
{"register_day":"3320915", "rtime":"tsukada", "lesson_date": "2019-06-30 14:02:04"}
{"register_day":"3320915", "rtime":"tsukada", "lesson_date": "2019-07-30 14:02:04"}
読み込ませる
bq load --source_format=NEWLINE_DELIMITED_JSON logs.cccc cccc.json
使ってみる
#standardSQL SELECT * FROM logs.cccc WHERE lesson_date BETWEEN '2017-01-01' AND '2019-10-01'
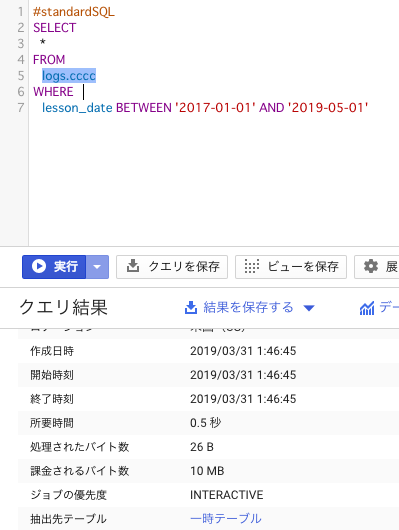
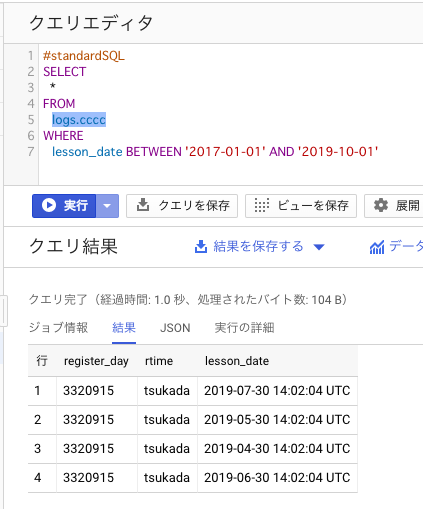
少数のデータなので記事としては微妙だが、最小単位の10Mが課金対象となる。