はじめに
GAE(Google App Engine)を使い始めたので、一度ここで整理をした。
app.yml
これがGAEの根幹
runtime: python27 api_version: 1 threadsafe: true handlers: - url: /.* script: main.app
使用する言語や、url /で受ける際に呼び出されるscript (この場合はmail.app)が書かれている。
scriptに書くこと
https://cloud.google.com/appengine/docs/standard/python/quickstart?hl=ja#mainpy
を少し終了し、編集した。
import webapp2
class MainPage(webapp2.RequestHandler):
def get(self):
self.response.headers['Content-Type'] = 'text/plain'
self.response.write('Wecome to Main Page')
class sub(webapp2.RequestHandler):
def get(self):
self.response.headers['Content-Type'] = 'text/plain'
self.response.write('This page is sub')
app = webapp2.WSGIApplication([
('/', MainPage),
('/sub', sub),
], debug=True)
/ でリクエストされるとMainPageクラスが呼び出され、
/subでリクエストがくるとsunクラスが呼び出されるという簡単なページ。
アプリケーションのテスト
Googleのプラットフォームにあげる前に、自身の環境でテストをすることが可能である。
dev_appserver.py app.yaml
ちなみに、dev_appserver.pyはgoogle-cloud-sdkをinstallすればbinの配下に入っている。
$ which dev_appserver.py /Users/sumito.tsukada/google-cloud-sdk/bin/dev_appserver.py
デフォルトでこのdev_appserver.pyを実施した場合、localhost:8080に繋げればアプリケーションの試験が可能だ
http://localhost:8080/
デプロイ
gcloud app deploy
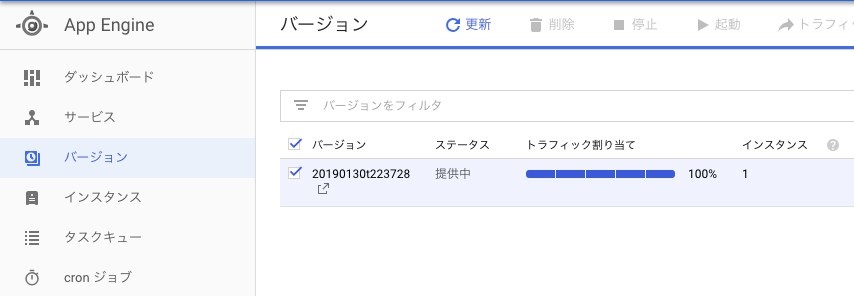
GAEコンソール画面
デプロイされたことを確認できた。
ブラウザ確認
自動でブラウザが立ち上がり動作確認をすることが可能。
gcloud app browse




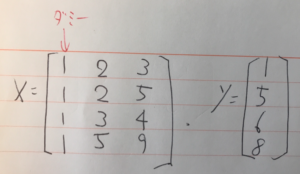
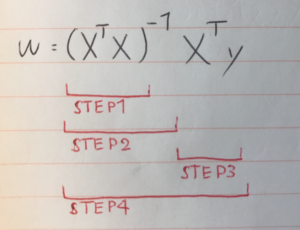
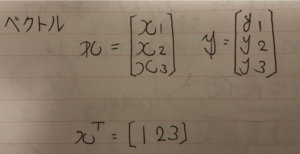
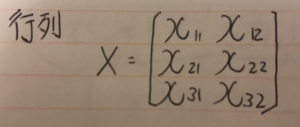
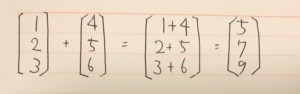
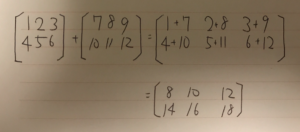
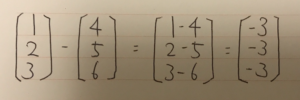
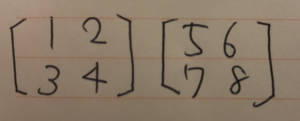
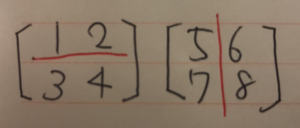
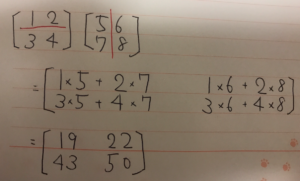
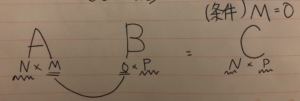
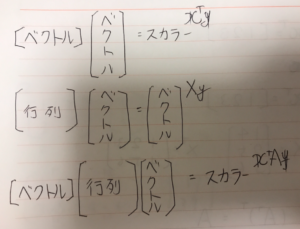
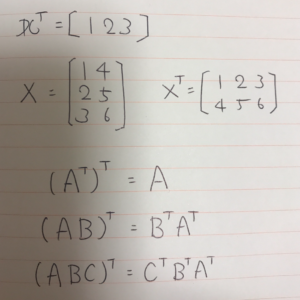

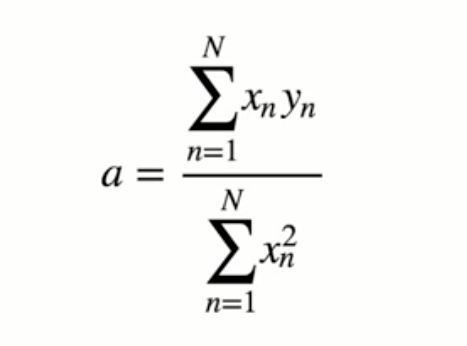 難しそうなインパクトが強すぎて中身がまったく頭に入ってこない。 これをnumpyで実装する。
難しそうなインパクトが強すぎて中身がまったく頭に入ってこない。 これをnumpyで実装する。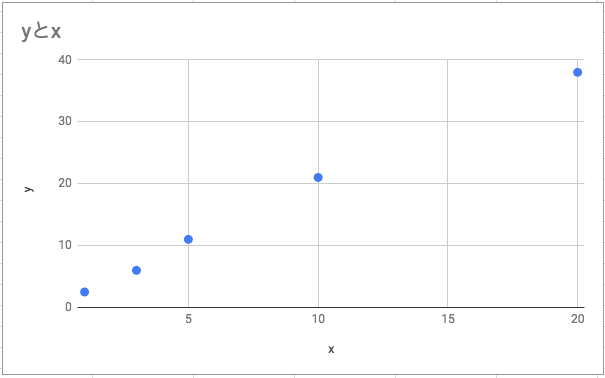 データの中心化を行う。値から、平均分を引く
データの中心化を行う。値から、平均分を引く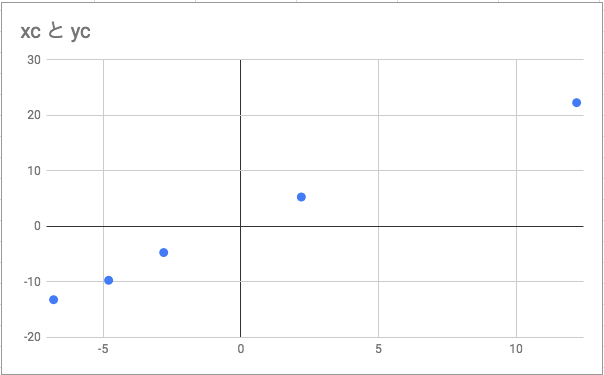
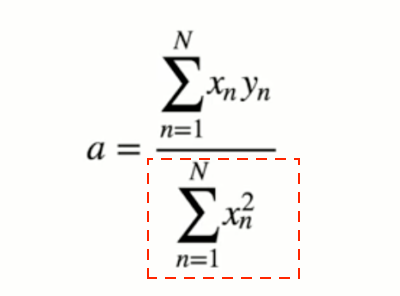 numpyで計算する際は、このようになる
numpyで計算する際は、このようになる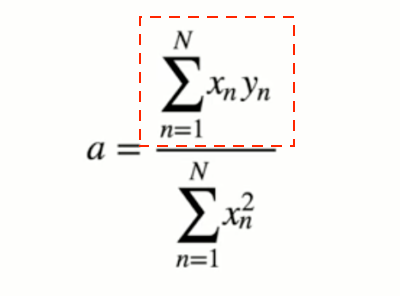 次に分子
次に分子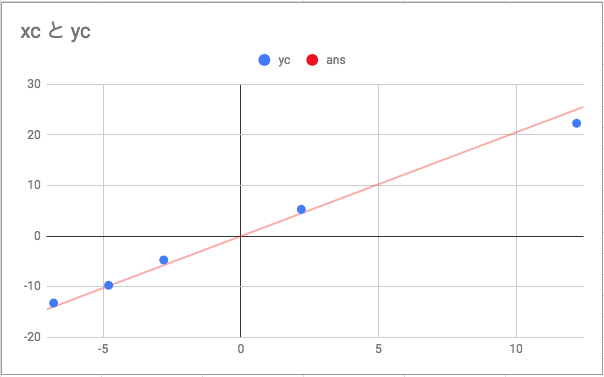 悪くなさそう。 実は実際はscikit-learnを使うともっと早いようだ。
悪くなさそう。 実は実際はscikit-learnを使うともっと早いようだ。 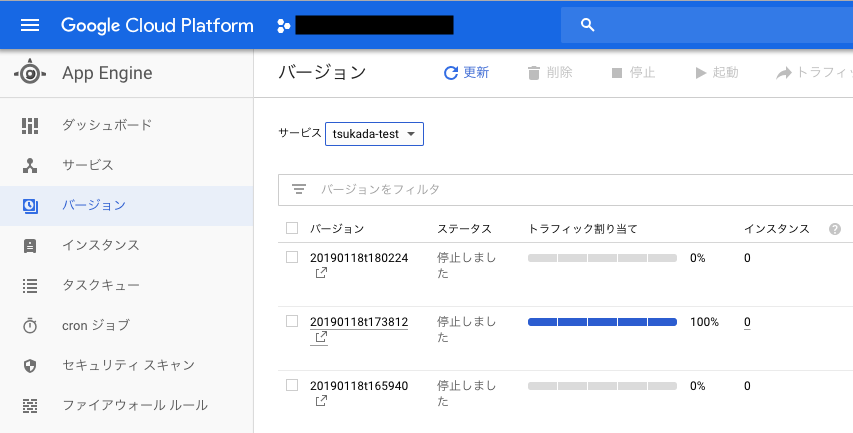 “` ./script.sh tsukada-test start “`
“` ./script.sh tsukada-test start “` 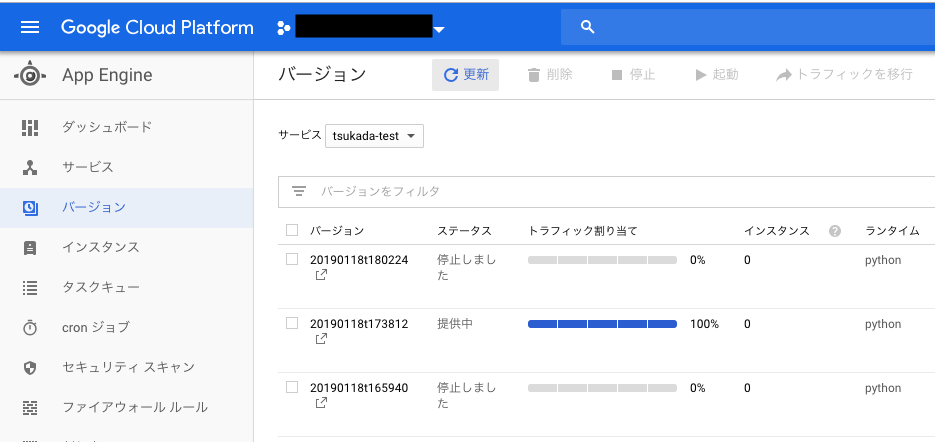 本来ならCloudFunctionで実装したかったが、大いにはまってしまったので、急遽この方法で対応した。
本来ならCloudFunctionで実装したかったが、大いにはまってしまったので、急遽この方法で対応した。 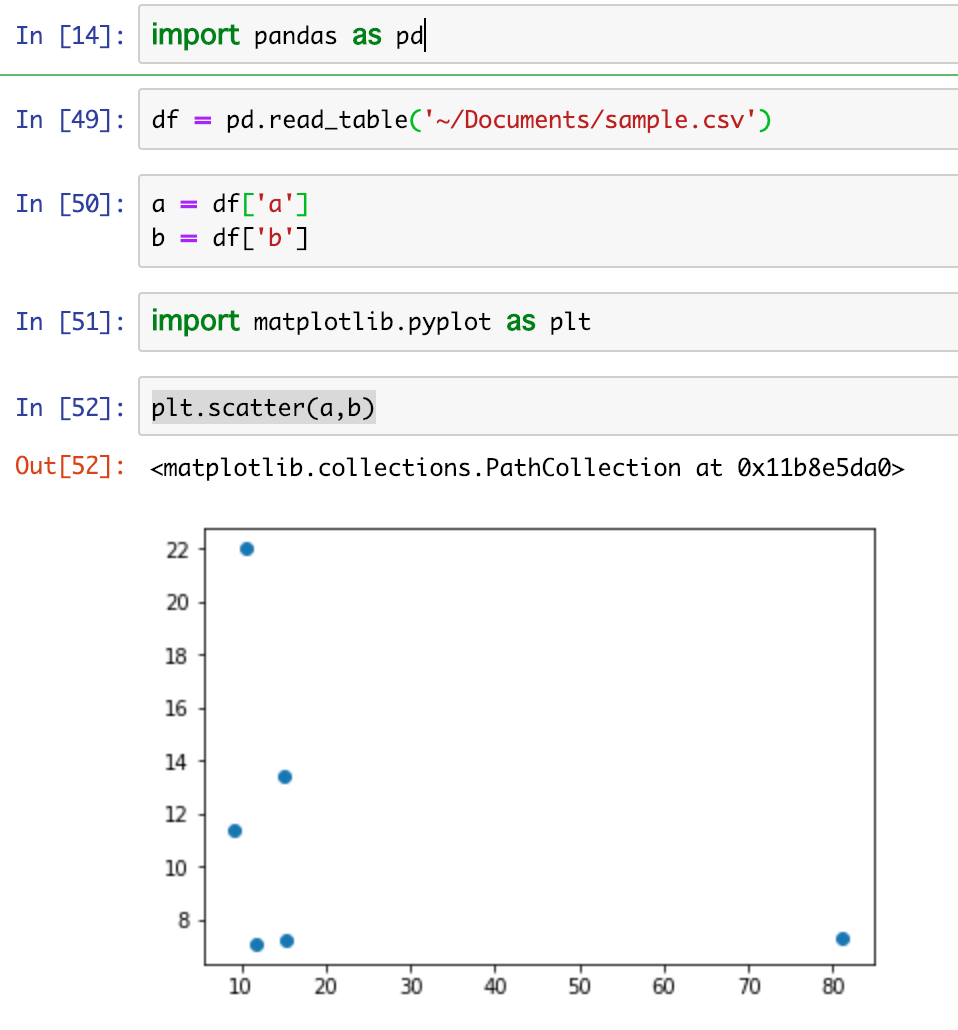
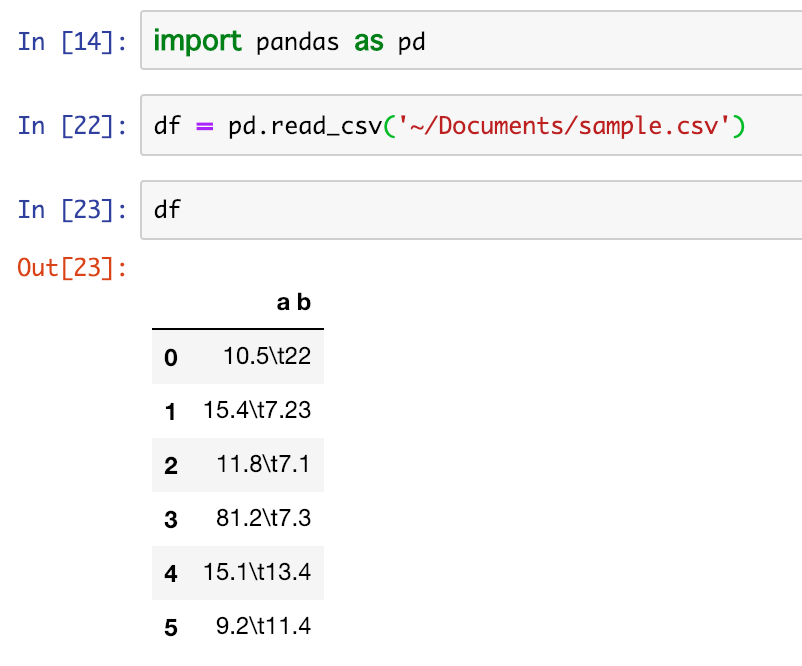 ちなみに読み込んだデータはこちら
ちなみに読み込んだデータはこちら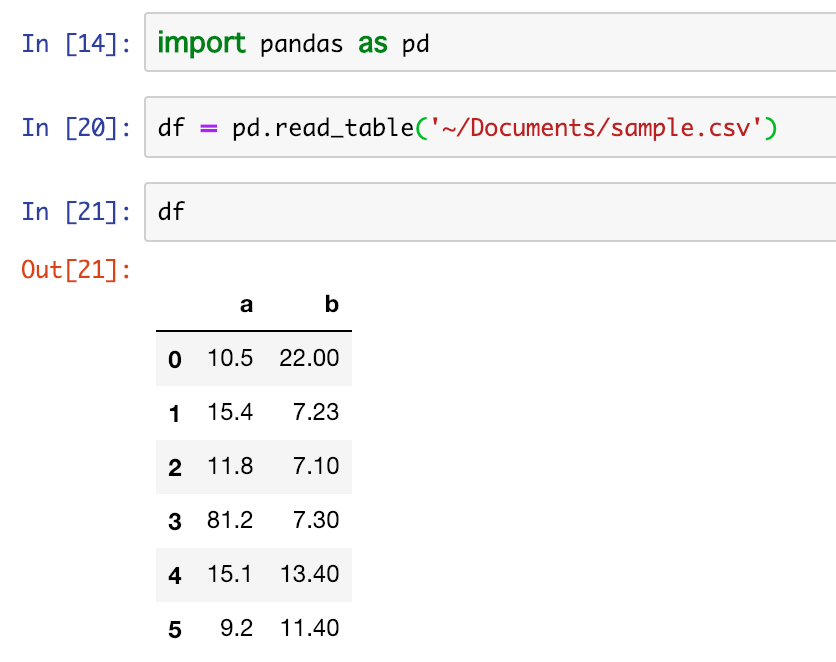 また、表示する件数を絞りたい場合はhead()を利用する
また、表示する件数を絞りたい場合はhead()を利用する 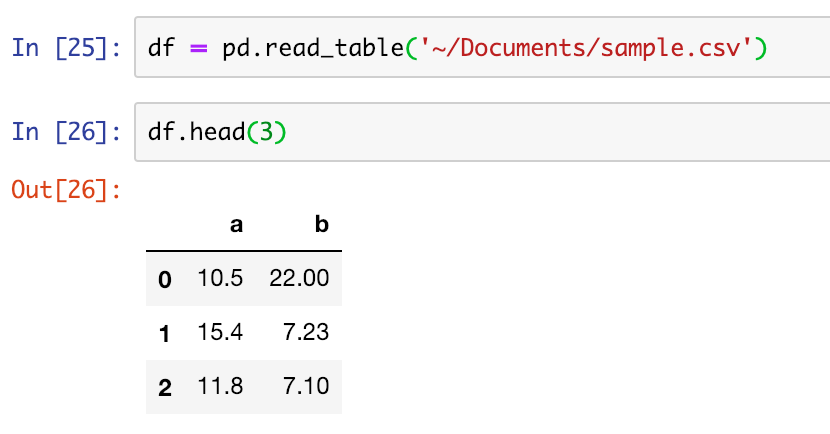 3を引数に渡すことで表示件数を3件に絞ることが可能になる。
3を引数に渡すことで表示件数を3件に絞ることが可能になる。