

はじめに
BigQueryでクエリスキャンを行うと、いくらwhereで絞ったとしても、テーブル内の指定したカラムは全行読み、それに応じて課金される。BigQueryに分割テーブル(partitioned table)を作成することにより、時間や日付を絞り膨大なスキャンならびに課金を限定的にすることが可能だ。今回はembulkからデータのinsertを行うことにする。
やりたいこと
MySQL -> (embulk) -> BigQuery
embulkの設定
in:
よしなに
out:
type: bigquery
auth_method: json_key
json_keyfile: xxxx.json
path_prefix: /tmp/
file_ext: .csv.gz
source_format: CSV
project: xxxxx
dataset: logs
time_partitioning:
type: DAY
auto_create_dataset: true
auto_create_table: true
delete_from_local_when_job_end: true
table: sample
formatter: {type: csv, charset: UTF-8, delimiter: ',', header_line: false}
encoders:
- {type: gzip}
パラメータの詳細はこちら
https://github.com/embulk/embulk-output-bigquery
実施
docker run -t -v ${PWD}:/work tsukada/embulk run bq.yml
結果(BigQuery)
select _PARTITIONTIME AS pt, lesson_date rtime from [logs.sample] WHERE _PARTITIONTIME >= "2018-11-13 00:00:00" AND _PARTITIONTIME < "2018-11-16 00:00:00"
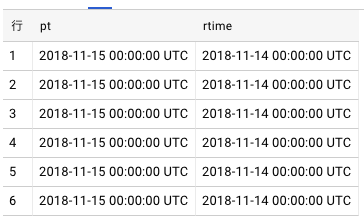
_PARTITIONTIMEは見えないカラムのようなもので、その日付はinsertで更新される。
WHERE _PARTITIONTIME でスキャン対象カラムを絞ることが可能。