

はじめに
DBサーバへ接続する際、readレプリカを複数台作ることが一般的だが、readレプリカに対してバランシングはインフラの設計ポイントとなる。auroraであれば自動でreadレプリカを作ってくれるのでその考慮は要らないがレガシーなシステムを運用している場合それは使えない。今回はAWSで組むこととする。
やりたいこと
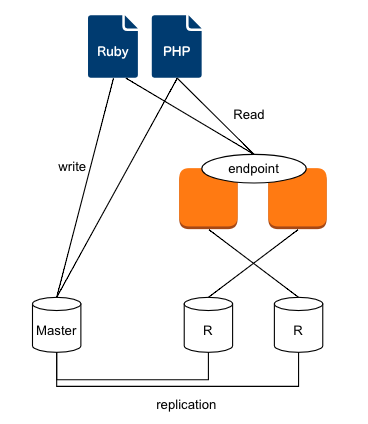
多くのプログラムはそうであろう構成。
プログラムは更新用(write)と参照用(read)で接続先を変え、
データベースはMasterとSlaveでレプリケーションをしている。
Slaveは今後増える可能性もあるのに加え、Slaveが1台ダウンしてもサービスが稼働できるようにするには、クラスタリング構成をする必要がある。
クラスタリングソフトの検討
| 名前 | 考察 |
|---|---|
| keepalived | 名前解決不可能。また、ググっても実績なし |
| HAProxy | Amazon linuxでyumでのversionが古い(1.5.2)。v1.6の resolvers オプションを使ってVPCのnameserverを参照するようにし、A Recordの変更に追従させる事が可能だが、ソースからのinstallになってしまう |
| MySQL Router | アルファ版 本番利用 非推奨 |
| Consul by HashiCorp | ググっても出ない |
| ProxySQL | AmazonLinux非対応 |
keppalivedはAWSでは難しいようだ。
今回はHA proxyで実現することにした。
対応
Amazon linuxの上にHAproxyを使いクラスタリングを実現する。
HAproxyのインストール
amazon linuxの場合、yumでinstallしようとすると、versionが古い。
そのため、sourceでインストールすることにした
yum install -y gcc cd /usr/local/src/ wget http://www.haproxy.org/download/1.8/src/haproxy-1.8.8.tar.gz pwd tar xvfz haproxy-1.8.8.tar.gz ls -ltr cd haproxy-1.8.8 make TARGET=generic make install
HAproxyの設定
設定は以下の通り
$ cat /etc/haproxy/haproxy.cfg
global
log tsukada01 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4096
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
stats maxconn 1
stats timeout 120s
resolvers awsvpc
nameserver vpc 172.20.0.2:53
defaults
mode tcp
log global
retries 3
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
maxconn 512
listen mysql
bind tsukada01:3306
mode tcp
option mysql-check user haproxy_check
balance roundrobin
option log-health-checks
server read01 dbserver01:3306 check port 3306 resolvers awsvpc inter 2000 fall 3
server read02 dbserver02:3306 check port 3306 resolvers awsvpc inter 2000 fall 3
もう片方のサーバは今の通りに設定した
$ cat /etc/haproxy/haproxy.cfg
global
log tsukada02 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4096
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
stats maxconn 1
stats timeout 120s
resolvers awsvpc
nameserver vpc 172.20.0.2:53
defaults
mode tcp
log global
retries 3
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
maxconn 512
listen mysql
bind tsukada02:3306
mode tcp
option mysql-check user haproxy_check
balance roundrobin
option log-health-checks
server read01 dbserver01:3306 check port 3306 resolvers awsvpc inter 2000 fall 3
server read02 dbserver02:3306 check port 3306 resolvers awsvpc inter 2000 fall 3
ほとんど同じように見えるので差分をまとめると、以下のような違いだ
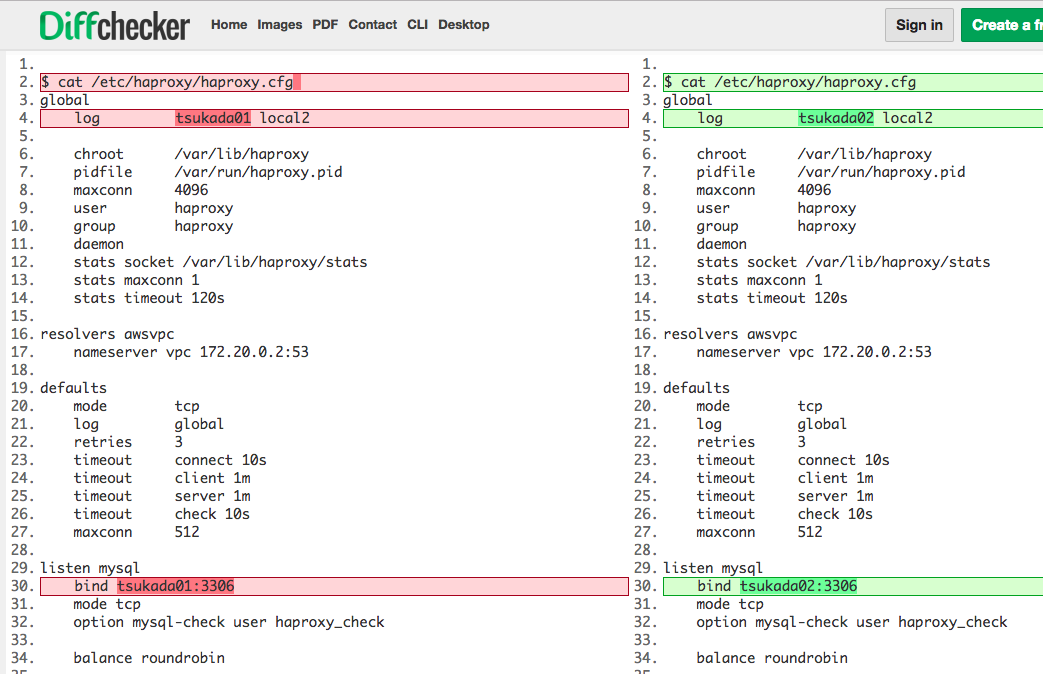
これで
- tsukada001の3306ポート
- tsukada002の3306ポート
に接続すると、dbserver01,dbserver02へラウンドロビンで接続されるようになった
しかし、これでは当然tsukada001、tsukada002自体で障害が起きる可能性もある。
ALBでバランシング
tsukada001:3306、tsukada002:3306をALBに登録しラウンドロビンで登録した。
これによりALBのエンドポイントが払い出され、それを各プログラムが参照するような形にして可用性を担保した。
振り返って見て思うこと
レガシーなDBでこの構成を組もうとすると、できないことはないが、登場人物がやたら多い。一番なのはauroraなどに移行し、本当に必要なことのみに集中できれば最高だ。