はじめに
データ解析するにあたり、BigQueryを使いたい事がある。mysqlからデータを取得するところをembulkを使う。embulkのインストール方法から簡単な使い方までまとめた。
embulkのインストール
embulkはJavaで作られており、一からinstallしようとすると、割と面倒。今回はDockerを使うこととする。
BigQueryの設定
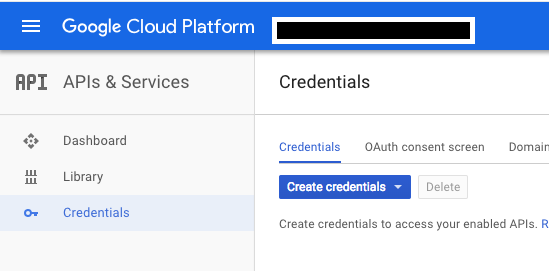
APIs & Servicesでcredentialを作成する。
jsonファイルダウンロードできるので、適宜保存する。
Dockerfileを作成
GCPにプロジェクトを作り、bigqueryに権限を付与。APIで操作できるようjsonファイルを取得する。
FROM java:7
MAINTAINER sumito.tsukada "tsukada@sumito.jp"
ENV EMBULK_VERSION 0.8.39
RUN curl -L https://bintray.com/artifact/download/embulk/maven/embulk-${EMBULK_VERSION}.jar -o /opt/embulk.jar
RUN java -jar /opt/embulk.jar gem install embulk-input-mysql
RUN java -jar /opt/embulk.jar gem install embulk-output-bigquery
WORKDIR /work
ENTRYPOINT ["java", "-jar", "/opt/embulk.jar"]
CMD ["--help"]
build
# docker build -t tsukada/embulk .
Sending build context to Docker daemon 2.048kB
Step 1/9 : FROM java:7
---> 5dc48a6b75af
Step 2/9 : MAINTAINER sumito.tsukada "tsukada@sumito.jp"
---> Using cache
---> bc78ed50d614
Step 3/9 : ENV EMBULK_VERSION 0.8.39
---> Using cache
---> 266476a95a55
Step 4/9 : RUN curl -L https://bintray.com/artifact/download/embulk/maven/embulk-${EMBULK_VERSION}.jar -o /opt/embulk.jar
---> Using cache
---> b21e71d6ce44
Step 5/9 : RUN java -jar /opt/embulk.jar gem install embulk-input-mysql
---> Using cache
---> 2fb224b24c49
Step 6/9 : RUN java -jar /opt/embulk.jar gem install embulk-output-bigquery
---> Running in b27f12583137
2018-09-18 02:50:32.526 +0000: Embulk v0.8.39
********************************** INFORMATION **********************************
Join us! Embulk-announce mailing list is up for IMPORTANT annoucement such as
compatibility-breaking changes and key feature updates.
https://groups.google.com/forum/#!forum/embulk-announce
*********************************************************************************
Gem plugin path is: /root/.embulk/jruby/2.3.0
Successfully installed uber-0.1.0
Successfully installed declarative-0.0.10
Successfully installed declarative-option-0.1.0
Successfully installed representable-3.0.4
Successfully installed retriable-3.1.2
Successfully installed public_suffix-3.0.3
Successfully installed addressable-2.5.2
Successfully installed mime-types-data-3.2018.0812
Successfully installed mime-types-3.2.2
Successfully installed multipart-post-2.0.0
Successfully installed faraday-0.15.2
Successfully installed multi_json-1.13.1
Successfully installed jwt-2.1.0
Successfully installed signet-0.9.2
Successfully installed memoist-0.16.0
Successfully installed os-1.0.0
Successfully installed googleauth-0.6.6
Successfully installed httpclient-2.8.3
Successfully installed google-api-client-0.24.0
Successfully installed thread_safe-0.3.6-java
Successfully installed tzinfo-1.2.5
Successfully installed time_with_zone-0.3.1
Successfully installed embulk-output-bigquery-0.4.9
23 gems installed
---> 74e55d0084d6
Removing intermediate container b27f12583137
Step 7/9 : WORKDIR /work
---> 19d9c56bf738
Removing intermediate container c73ef21e7b6c
Step 8/9 : ENTRYPOINT java -jar /opt/embulk.jar
---> Running in 4bca2f2ed68e
---> b4458584af6f
Removing intermediate container 4bca2f2ed68e
Step 9/9 : CMD --help
---> Running in 7fdbd68d5021
---> 0bfdab6b8d24
Removing intermediate container 7fdbd68d5021
Successfully built 0bfdab6b8d24
Successfully tagged tsukada/embulk:latest
embulkの設定
今回はmysqlからデータを抜き、BigQueryに入れるとする。
in:
type: mysql
user: redash
password: passwd
database: sample
host: 127.0.0.1
query: "select date, user from sampletable"
out:
type: bigquery
auth_method: json_key
json_keyfile: tsukada-bigquery.json
path_prefix: /tmp/
file_ext: .csv.gz
source_format: CSV
project: 12345679
dataset: table123
auto_create_table: true
table: user_data
formatter: {type: csv, charset: UTF-8, delimiter: ',', header_line: false}
encoders:
- {type: gzip}
実行
docker run -t -v ${PWD}:/work tsukada/embulk run sample.yml
以下のようい表示されればOK
[INFO] (main): Committed.
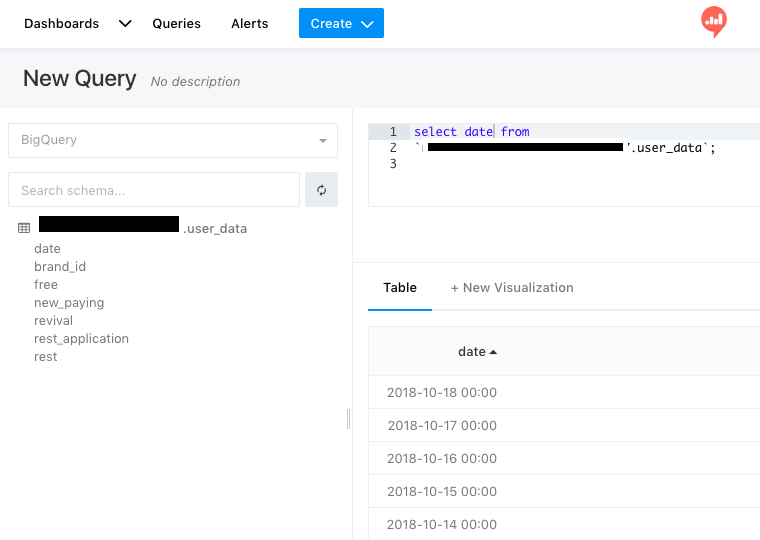
BigQueryで確認
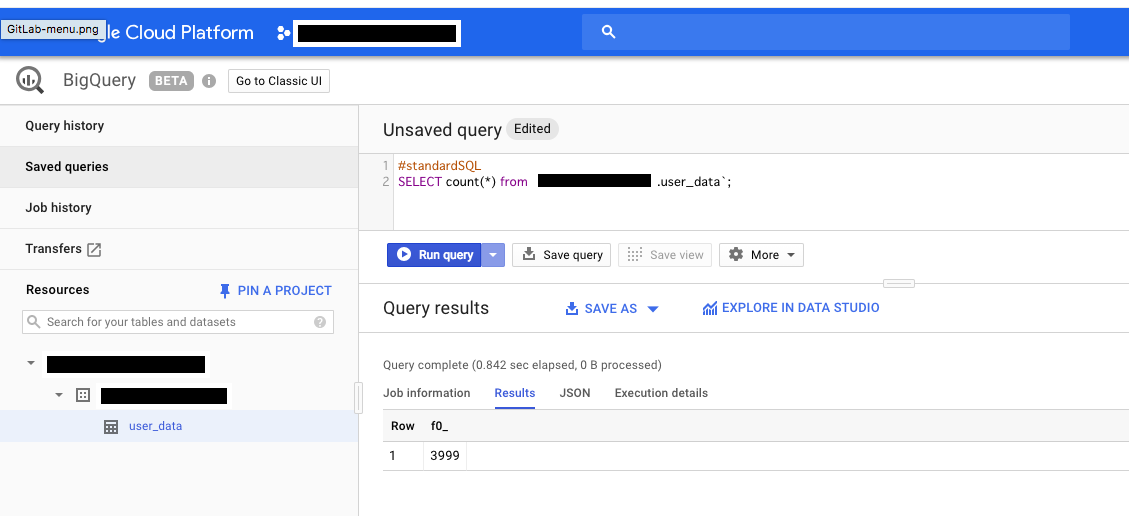
データが入ったという事がわかった。
また、
#standardSQL
と書いてあるが、これはコメントではなく、BigQueryが判断する重要な宣言になるので削除するとうまく動かないので注意。
redashでBigQueryに接続
先ほど使ったjsonファイルと接続先のプロジェクトIDを入力すると、redashからbigqueryへ接続する事ができる。